Unüberwachte Lernmethoden für Vorverarbeitung und Evaluation von Testdaten: Ein Beispiel mit Dimensionsreduktionsverfahren und Formel-1-Telemetriedaten
TLDR
Beim Testen von Fahrzeugen fallen enorme Mengen an Zeitserien-Daten an. Mit KI-Methoden können die Daten vorverarbeitet und wichtige Abschnitte automatisch markiert werden. Dies kann mit unüberwachten Lernmethoden auch ohne Labeling und Training durchgeführt werden. Ähnlichkeiten in Zeitserien können verwendet werden, um Daten zu strukturieren und dem Benutzer wichtige Datenpunkte interaktiv zu visualisieren.
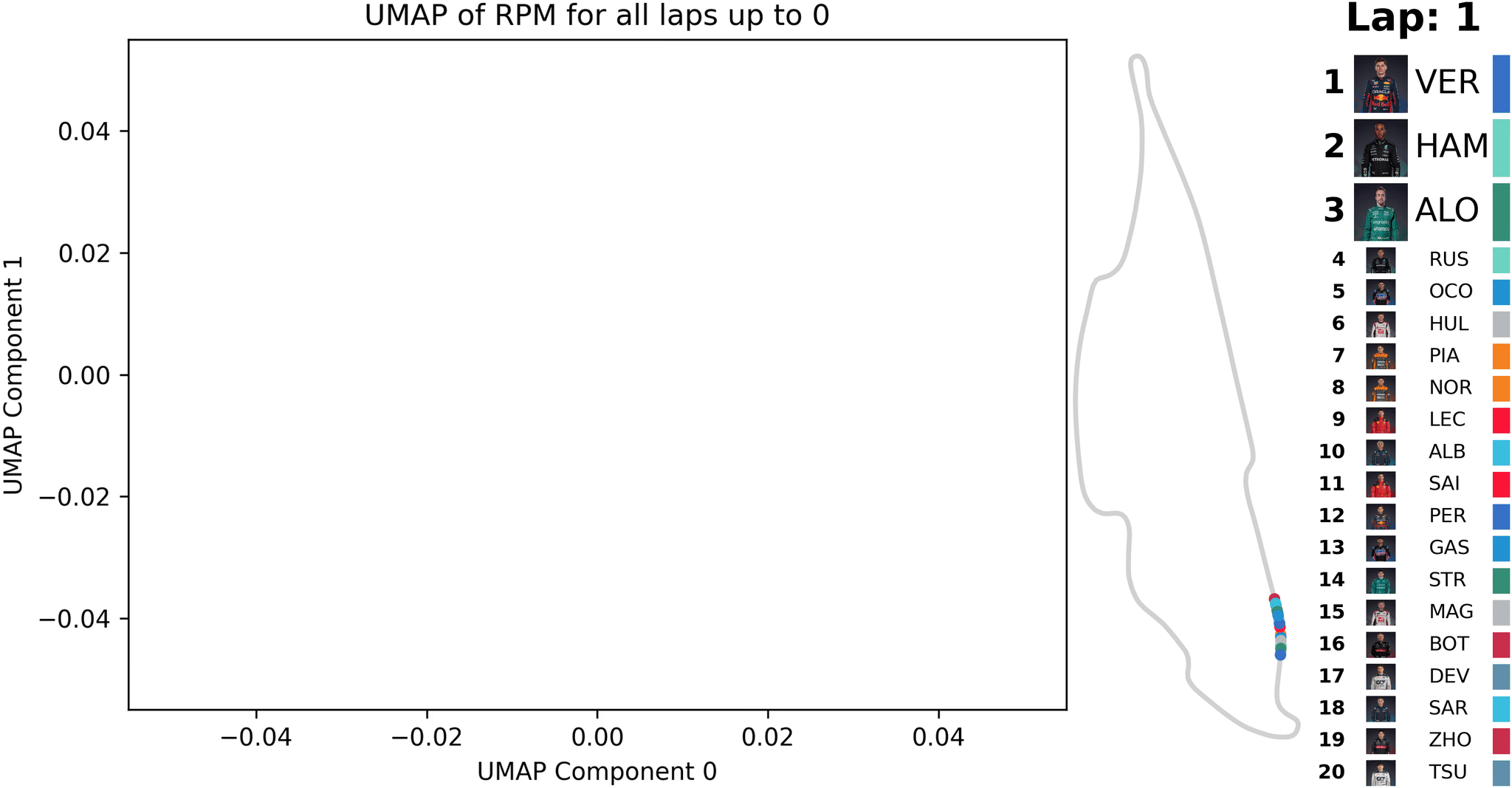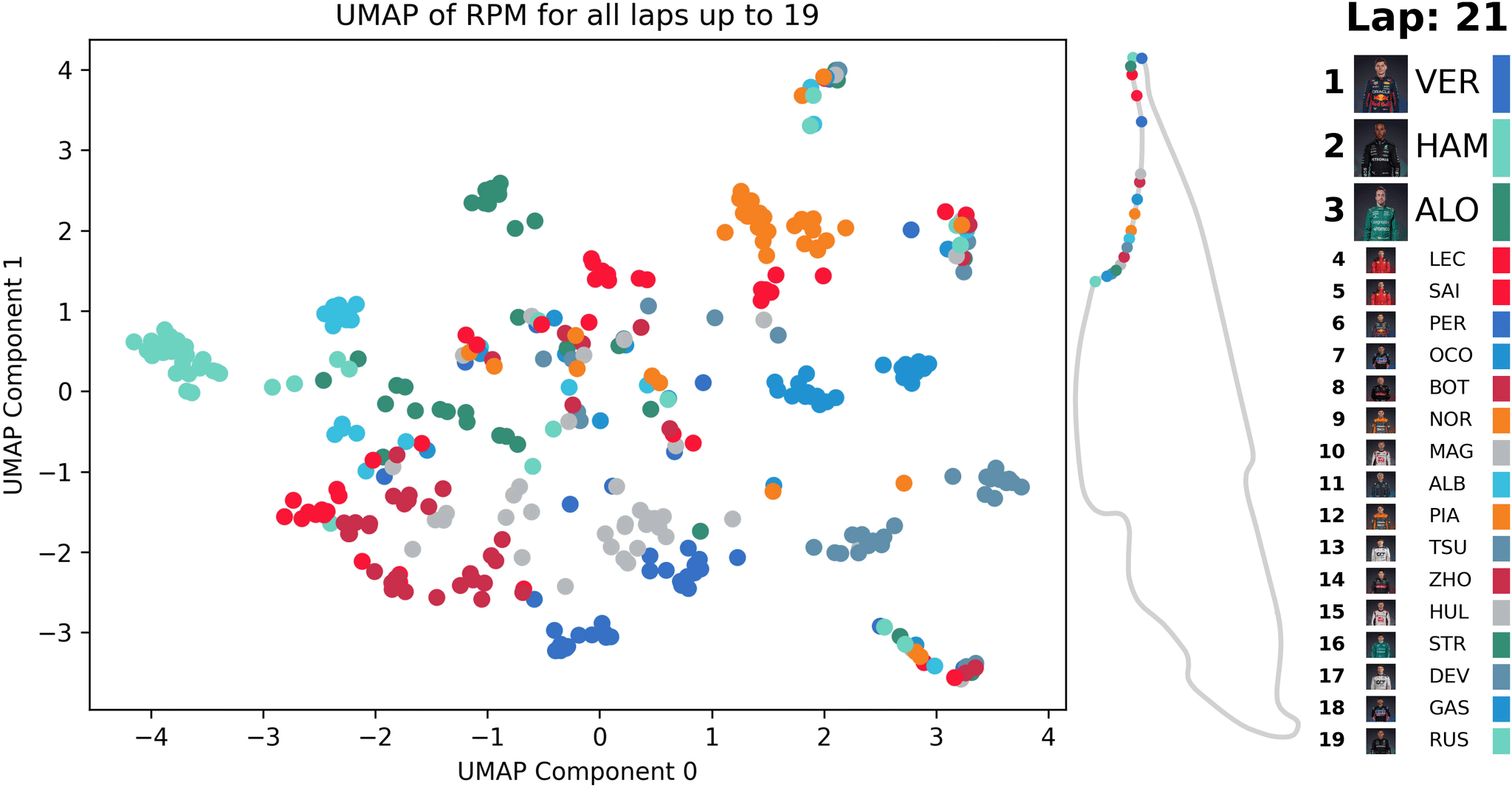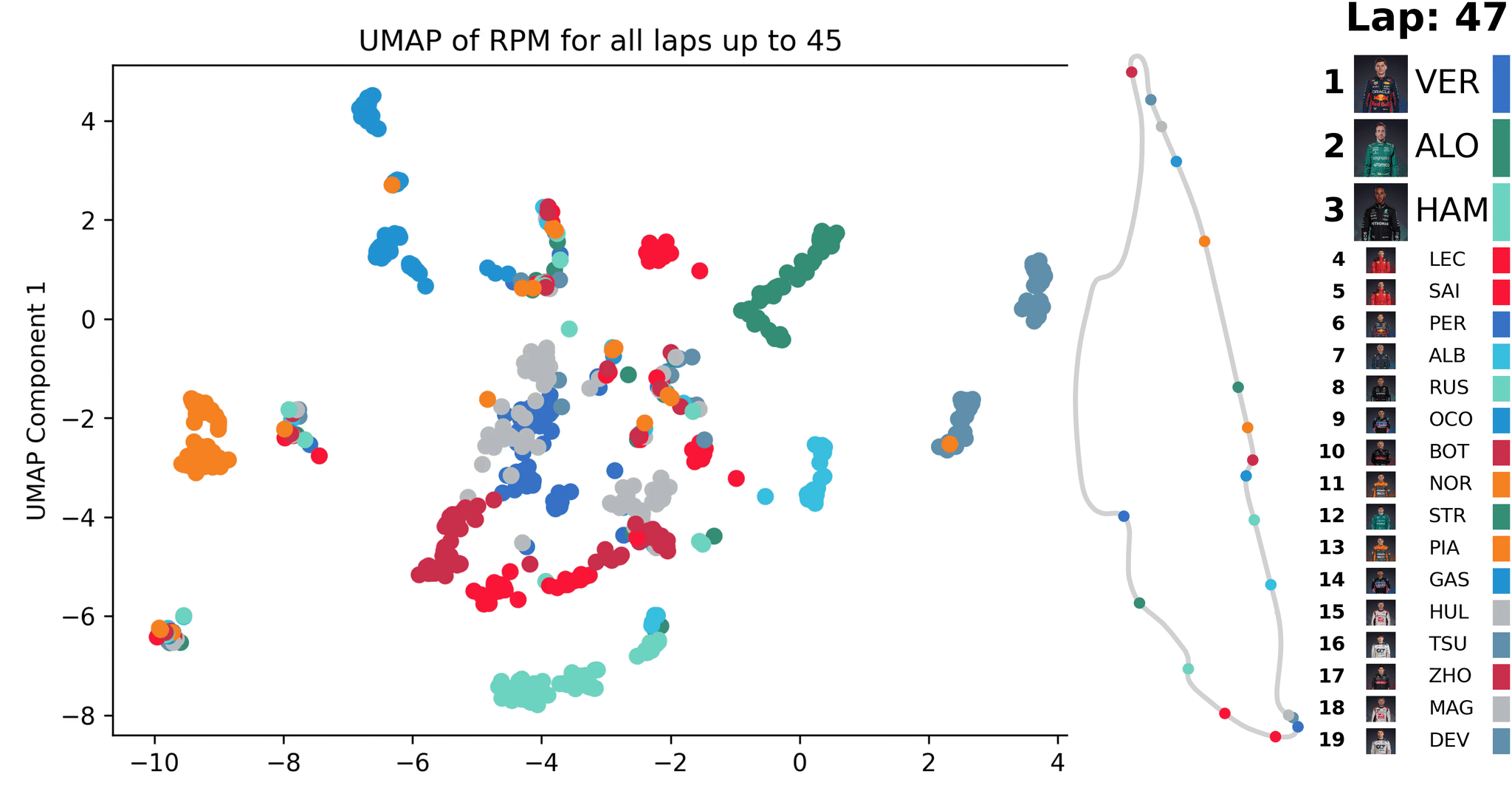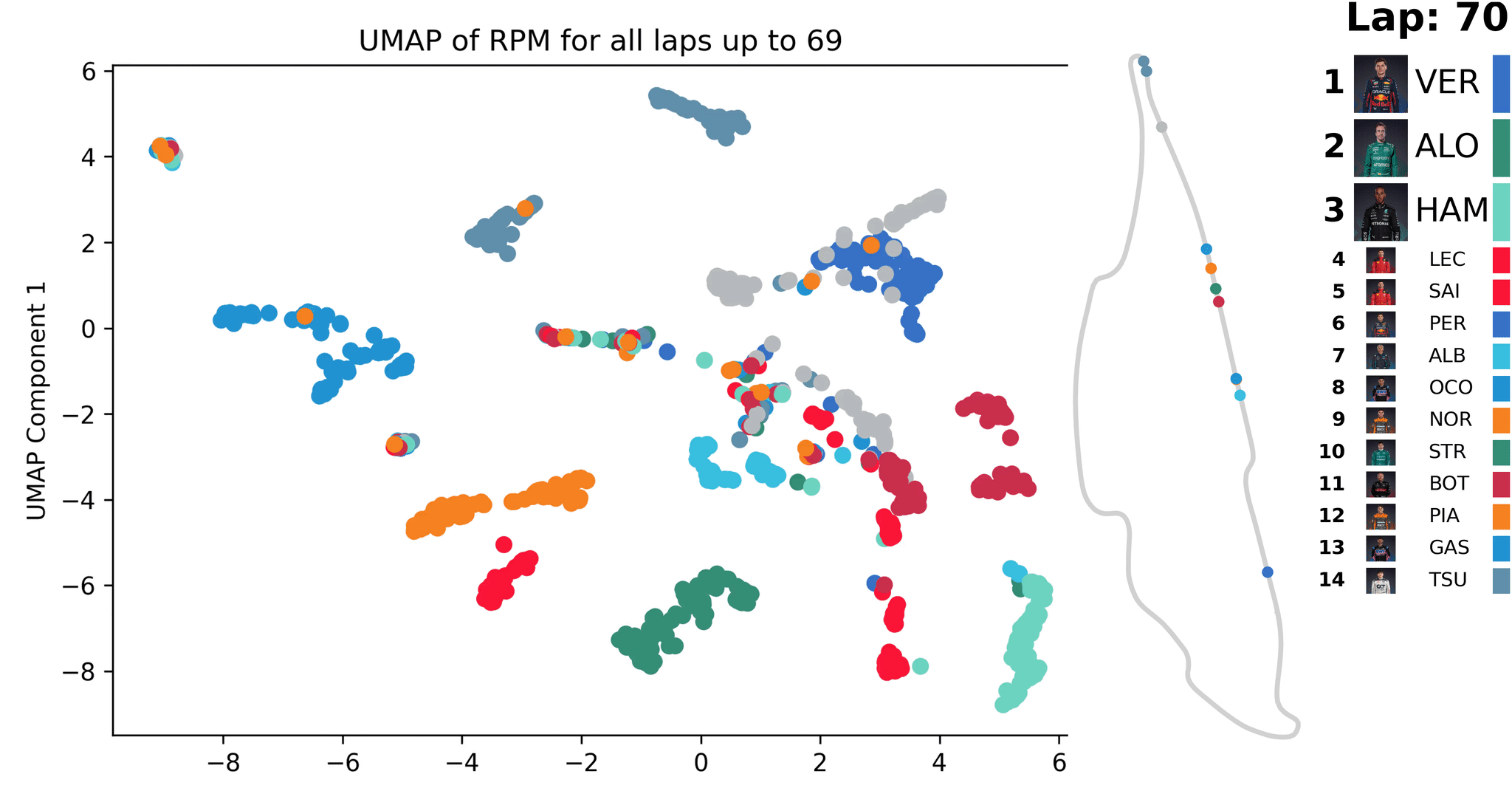 Animation der UMAP-Dimensionalitätsreduktion [1] für Telemetriedaten (RPM) eines Formel-1-Rennens; die Reduktion wird mit den Daten jeder neuen Runde aktualisiert
Animation der UMAP-Dimensionalitätsreduktion [1] für Telemetriedaten (RPM) eines Formel-1-Rennens; die Reduktion wird mit den Daten jeder neuen Runde aktualisiert
In der Animation wird eine solche ähnlichkeitsbasierte Analyse dargestellt. Es werden exemplarisch Telemetriedaten (RPM - Motordrehzahl in Umdrehungen pro Minute) eines Formel-1-Rennens betrachtet. Nach jeder gefahrenen Runde eines F1 werden alle Daten der bisherigen Runden ausgewertet und für deren RPM-Verläufe ein Punkt auf der Ähnlichkeitskarte berechnet. Über die Zeit sieht man, wie sich Muster bilden. Dies kann dazu verwendet werden, außergewöhnliche Ereignisse zu finden, die dann genauer inspiziert werden können.
Herausforderungen beim Testen von Fahrzeugen
Das Testen ist essenziell für die Entwicklung von sicheren und komfortablen Fahrzeugen. Die dabei generierten Messdaten und Telemetriedaten vom CAN-Bus sowie Sensordaten oder Audioaufnahmen sind jedoch aufgrund der vielen Kanäle, langer Messzeiten und zahlreiche Testvariationen sehr umfangreich. Eine effiziente Auswertung der Daten aus verschiedensten Testverfahren in Bereichen wie Noise, Vibration, Harshness (NVH), Antriebsstrang, Elektrische und Elektronische Integration, Advanced Driver Assistance Systems (ADAS) oder Passive Sicherheit ist daher eine Herausforderung.
Lösungen mit KI für Testdatenanalyse in der Fahrzeugprüfung
Manchmal reichen einfache, regelbasierte Verfahren, um Daten automatisiert vorzuverarbeiten und die Arbeit zu reduzieren. Meist ist jedoch erfahrungsbasierte manuelle Arbeit notwendig, um ungewöhnliche Ereignisse zu finden. Dies kann durch eine automatische Vorverarbeitung verkürzt werden. Mit verschiedenen KI-Verfahren für die Testdatenanalyse können Kandidaten für Ereignisse gefunden und nach ihrer Auffälligkeit sortiert werden:
Überwachtes KI-Verfahren: Falls bereits ausgewertete Daten mit Annotationen für stattgefundene Ereignisse verfügbar sind, kann es sinnvoll sein, damit ein überwachtes KI-Verfahren zu trainieren, das beispielsweise die Detektion von spezifischen Ereignissen wie Bremsenquietschen in den Daten ermöglicht.
Unüberwachte Verfahren: Diese Verfahren können ohne Labeling und Training die Daten strukturieren.
-
Clustering: Hier werden ähnliche Datenpunkte in Cluster zusammengefasst. Dies hilft dabei Gemeinsamkeiten in den Daten effizient zu nutzen, beispielsweise indem bei der Analyse nur einzelne repräsentative Vertreter jedes Clusters betrachtet werden, um Zeit zu sparen.
-
Dimensionsreduktionsverfahren: Dimensionsreduktionsverfahren können verwendet werden, um hochdimensionale Daten in eine niedrigdimensionale Darstellung zu projizieren. Beispielsweise können die Zeitsequenzen interpoliert und mit UMAP in ein 2D-Bild projiziert werden, um eine anschauliche Darstellung zu generieren. Dabei werden lokale und globale Strukturen so gut es geht beibehalten.
Ein Beispiel mit Formel-1-Telemetriedaten
Das Vorgehen für Dimensionsreduktionsverfahren kann mit wenigen Zeilen Code nachvollzogen werden:
Zunächst wird die Umgebung eingerichtet: Es wird ein Jupyter Notebook gestartet und die benötigten Pakete installiert:
!pip install fastf1 pandas umap-learn renumics-spotlight
Die folgenden Pakete werden verwendet:
-
FastF1: Python-Bibliothek für einfachen Zugriff auf historische F1-Daten (Telemetrie und Rennergebnisse).
-
Pandas: Pythonbibliothek für Datenanalyse.
-
umap-learn: Pythonbibliothek für Dimensionsreduktion, die hochdimensionale Daten in eine niedrigdimensionale Darstellung projiziert, wobei lokale und globale Datenstrukturen erhalten bleiben.
-
Renumics-Spotlight: Unser Tool für interaktive Visualisierung von strukturierten und unstrukturierten Daten.
Nun wird die Renn-Telemetrie über die FastF1-Schnittstelle geladen:
import fastf1
session = fastf1.get_session(2023, "Montreal", "Race")
session.load(telemetry=True, laps=True)
Jetzt kann für jeden Fahrer jede Runde als DataFrame abgefragt werden. Dies beinhaltet unter anderem:
-
Driver: Fahrer des Fahrzeugs
-
LapNumber: Nummer der aktuellen Runde
-
Speed (Zeitreihe): Geschwindigkeit
-
Throttle (Zeitreihe): Gaspedalstellung
-
Brake (Zeitreihe): Verwendung der Bremse
-
RPM (Zeitreihe): Motordrehzahl
-
X (Zeitreihe): Die X-Koordinate, die die Position des Fahrzeugs auf der Strecke angibt
-
Y (Zeitreihe): Die Y-Koordinate, die die Position des Fahrzeugs auf der Strecke angibt
Die Daten werden dann zunächst mit
def dataframe_to_dict(df):
"""Converts a pandas DataFrame to a dictionary of lists.
If a column has only one unique value, it is converted to a scalar."""
result = {}
for col in df.columns:
unique_values = df[col].unique()
result[col] = df[col].tolist() if len(unique_values) > 1 else unique_values[0]
return result
in einzelne Dictionaries für Telemetrie und allgemeine Informationen umgewandelt. Die Zeitreihen werden in Listen umgewandelt:
# Load lap info and telemetry as list of dicts
df_laps_telemetry, laps = [], []
for _, lap in session.laps.iterlaps():
df_laps_telemetry.append(lap.get_telemetry())
laps.append(lap.to_dict())
Jetzt werden alle Dictionaries verwendet,
# create a new DataFrame with one row for each lap of each driver
import pandas as pd
data = [dataframe_to_dict(tele) | lap for lap, tele in zip(laps, df_laps_telemetry)]
df = pd.DataFrame(data)
um ein großes DataFrame zu erstellen:
| Date | Driver | LapNumber | Speed | RPM | Brake | X | ... | |
|---|---|---|---|---|---|---|---|---|
| 0 | [Timestamp('2023-06-18, ...] | VER | 1 | [0, 0, 0, ...] | [9812, 9753, ... ] | [False, False, ...] | [3299, 3300, ...] | |
| 1 | [Timestamp('2023-06-18, ...] | VER | 2 | [278, 278, ...] | [11033, 11045, ...] | [False, False, ...] | [3356, 3374, ...] | |
| 2 | [Timestamp('2023-06-18, ...] | VER | 3 | [279, 280, ...] | [11008, 11007, ...] | [False, False, ...] | [3356, 3376, ...] |
Um die weiteren Schritte zu vereinfachen, werden die zu analysierenden Datenreihen interpoliert:
import numpy as np
def interpolate_column(values):
"""Interpolates a list of values to a fixed length of 882."""
x = np.linspace(0, 1, 882)
xp = np.linspace(0, 1, len(values))
return np.interp(x, xp, values)
sodass alle Zeitreihen die gleiche Länge haben:
df["Speed_emb"] = df["Speed"].apply(interpolate_column)
df["RPM_emb"] = df["RPM"].apply(interpolate_column)
Dann kann ihre Dimensionalität reduziert werden:
import umap
import numpy as np
embeddings = np.stack(df["Speed_emb"].to_numpy())
reducer = umap.UMAP()
reduced_embedding = reducer.fit_transform(embeddings)
df["Speed_emb_umap"] = np.array(reduced_embedding).tolist()
Das Ergebnis kann angezeigt und mit geeigneten Visualisierungstools exploriert werden. In diesem Beispiel wird Renumics-Spotlight verwendet
import pandas as pd
from renumics import spotlight
spotlight.show(df, dtype=\{"Speed": spotlight.Sequence1D\}, port=5436)
um eine interaktive Visualisierung des DataFrames zu starten:
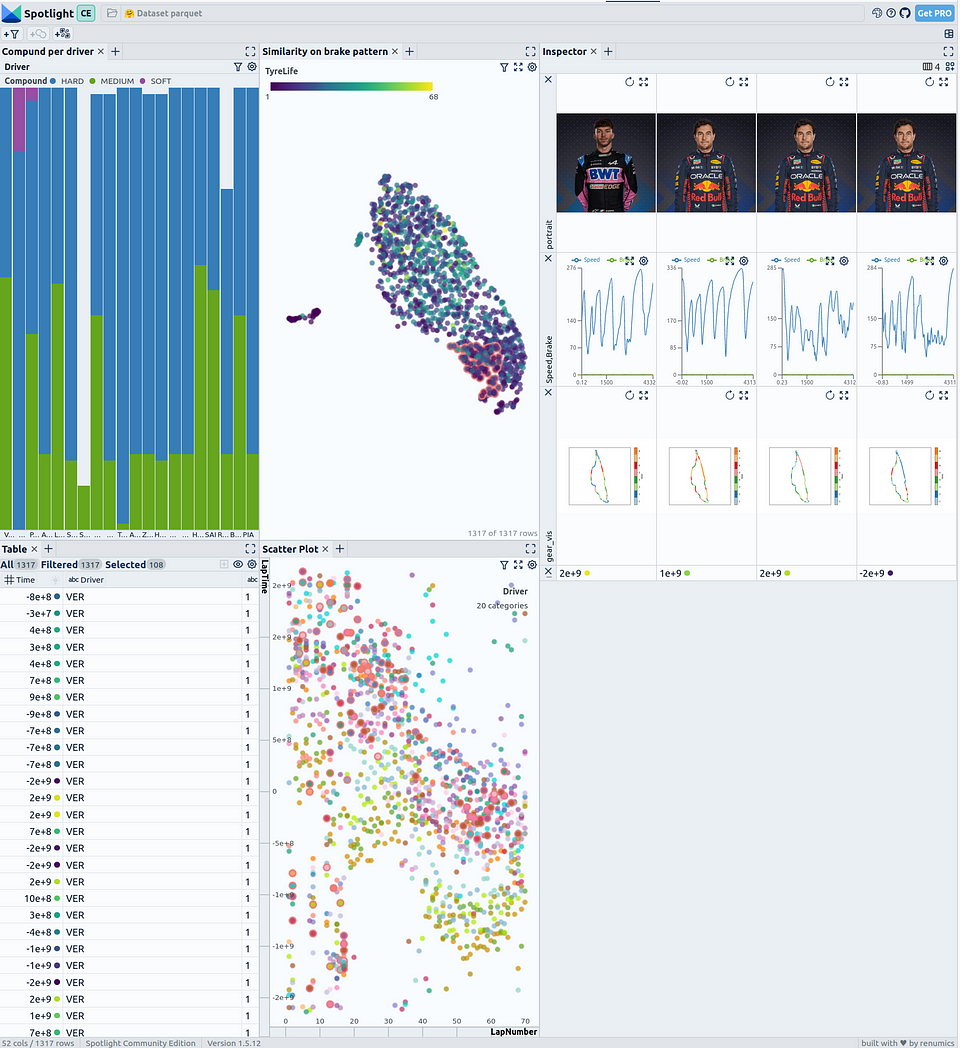
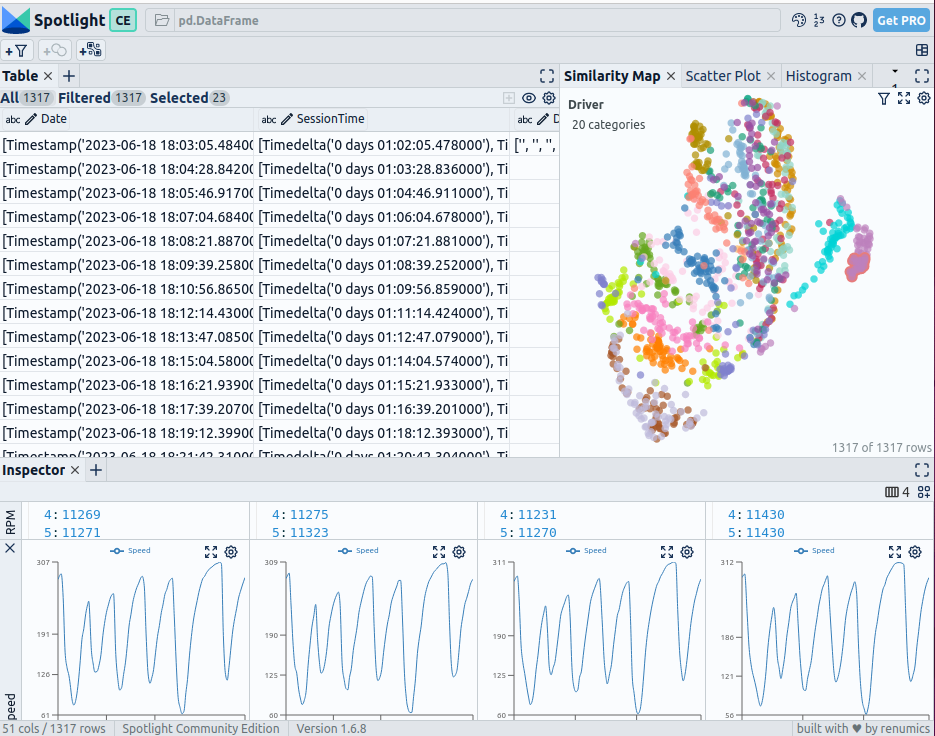 Interaktive Visualisierung der Formel-1-Renndaten mit Renumics Spotlight
Interaktive Visualisierung der Formel-1-Renndaten mit Renumics Spotlight
In der linken Tabelle wird das DataFrame angezeigt. Mit dem Button "visible columns" können Sie steuern, welche Spalten in der Tabelle angezeigt werden. Die Ähnlichkeitskarte wird oben rechts angezeigt. Ausgewählte Datenpunkte werden unten angezeigt, wo das Geschwindigkeitsprofil geplottet wird.
Erweitertes Beispiel auf Hugging Face
In unserem Demo-Space auf Hugging Face haben wir ein weiteres Beispiel erstellt, das neben der Zeitreihe eine Visualisierung des Streckenlayouts mit farbcodierten Darstellungen für Geschwindigkeit und Gang sowie Porträts der einzelnen Fahrer enthält:
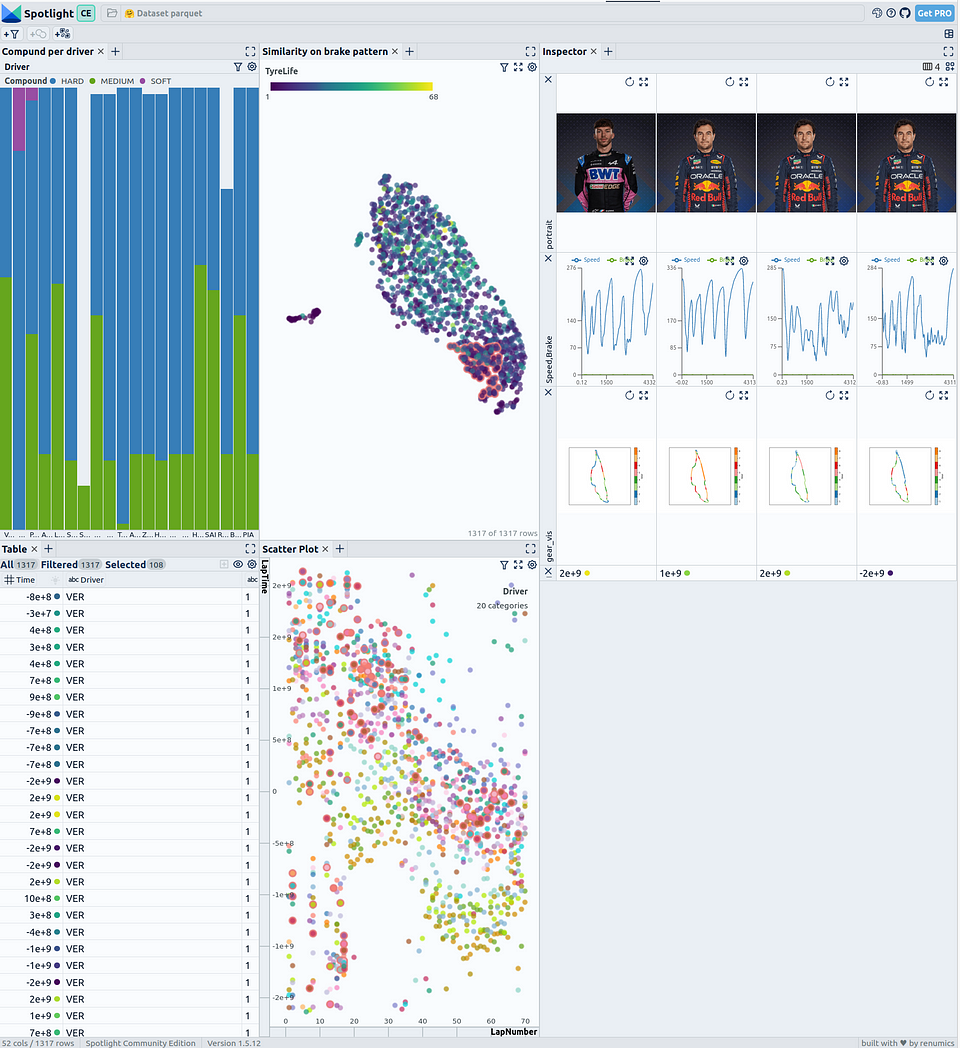 Screenshot unseres Formel 1 Demo Space auf Hugging Face
Screenshot unseres Formel 1 Demo Space auf Hugging Face
Mit der Visualisierung des Streckenlayouts können die Fahrzeugdaten aus dem Rennen einfacher analysiert werden. Die farbcodierte Darstellung von Geschwindigkeit und Gang ermöglicht es, kritische Punkte auf der Strecke und die unterschiedlichen Strategien der Fahrer zu identifizieren.
Zusammenfassung
Die Verwendung von KI-Methoden zur halbautomatischen Auswertung von Testdaten im Automobilsektor bietet erhebliche Vorteile. Unüberwachte Lernmethoden wie Clustering und Dimensionsreduktionsverfahren ermöglichen die effiziente Analyse großer Zeitreihendatensätze durch automatisches Markieren relevanter Abschnitte. Dies hilft, ungewöhnliche Ereignisse schneller zu identifizieren und kann den Entwicklungsprozess beschleunigen.
Das Beispiel der Dimensionsreduktionsverfahren für Formel-1-Telemetriedaten zeigt, wie Testdaten strukturiert und visuell durch Dimensionsreduktionsverfahren verarbeitet werden können.
Referenzen
[1] Leland McInnes, John Healy, James Melville: UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction (2018), arXiv