Testing complex systems such as vehicles, aircraft or machinery generates a huge amount of data due to high sampling frequencies, hundreds of data channels, and large test fleets. Naturally, only a tiny amount of the data can be used to identify potential problems and gain insights for product development. This is not necessarily a problem as most of the data is irrelevant anyway. However, the challenge is to identify the circumstances or events that do matter. A trusted strategy is to use some domain knowledge and formulate triggers both during the data acquisition and the analysis phase: In case of a car this might be a situation where gears are shifted, or the brakes are activated. However, with this strategy an engineer must know in advance where to look. In addition, some situation cannot be expressed with simple triggers and even if that is possible, the amount of data left can still be overwhelming.
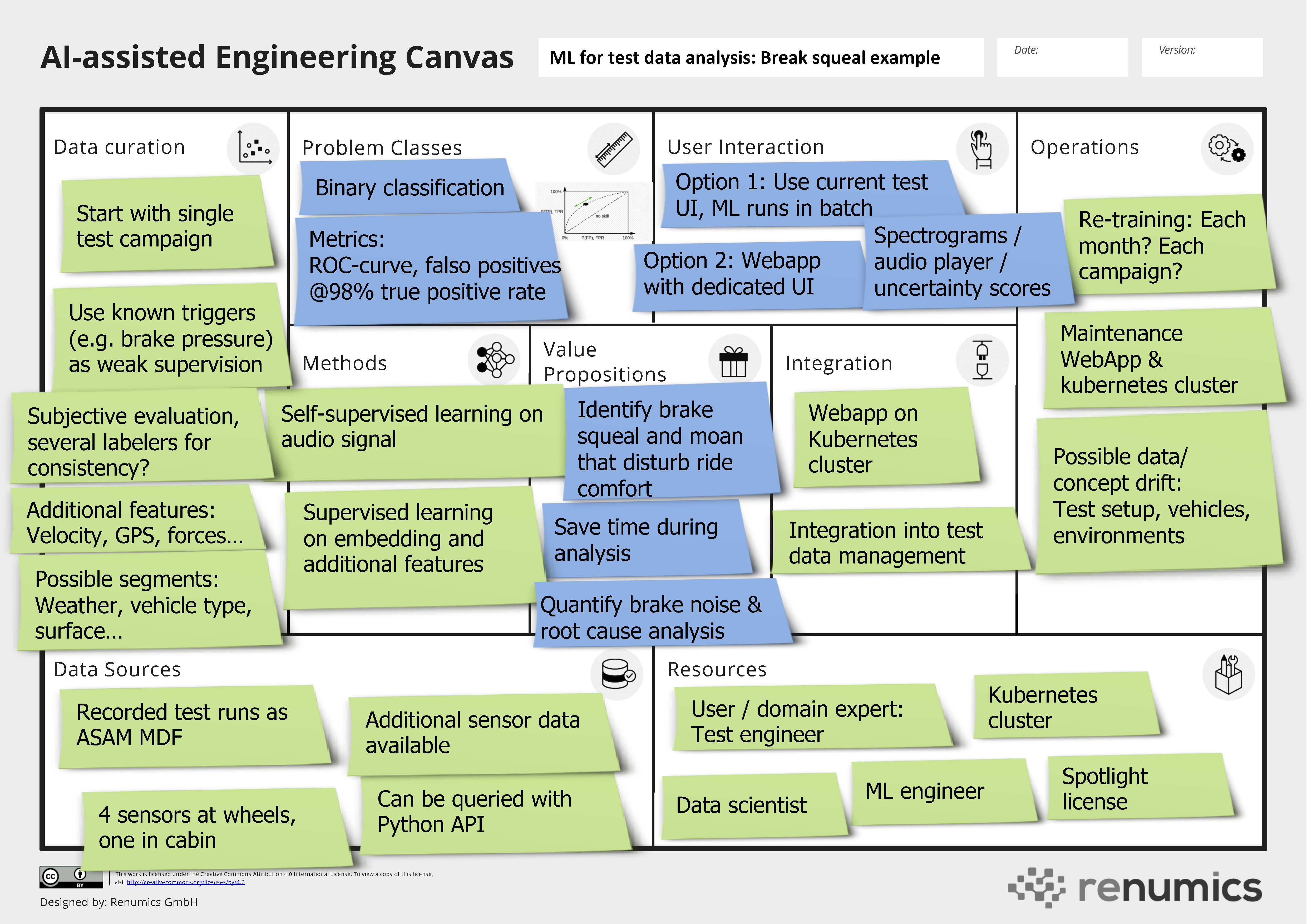
A promising approach that significantly reduces the time to find meaningful events in testing data is to rely on machine learning technology. In this blog we present a concrete use case for this type of application: Identifying brake squeal and moan during vehicle testing. We use the AI-assisted Engineering Canvas as a template to holistically present the use case. As this presentation should be concise and readable, we might simplify some concepts within this article. Here is the tl;dr summary in terms of the canvas:
Background on the use case
Low noise levels and overall acoustic comfort are important properties of quality cars. In this context, brake noises are perceived as very annoying by the customers. Reducing and eliminating braking noise has been a research topic for decades in both academia and industry. An important step in the development process is to identify potential moan (frequencies below 1kHz) and squeal (above 1kHz) noises during testing. For this purpose, the test vehicle is equipped with different microphones to capture the brake sound. An established strategy is to combine relevant trigger values such as brake pressure with simple filtering techniques to identify squeal and moan [1]. However, this detection method is not very accurate and thus it takes a significant amount of time to sort out false positives from the flagged test data. In addition, it is desirable to perform additional quantification and classification on the noise event. Machine learning methods from computer vision can potentially provide this information with better accuracy [2]. This would significantly speed up the test data analysis time.
Value proposition, User interaction and problem class
The core value proposition is to save time during test data analysis by reducing the number of events that must be reviewed. We can quantify that as hours saved per test campaign or as a percentage of the overall data analysis time. We can also unlock additional gains with the solution that are more difficult to measure: It can assist in quantifying the braking noise and in finding insights and root causes through similarity analysis over the data points. The solution might also uncover errors and behaviors that were previously unnoticed.
Different user interactions with different degrees of complexity and integration effort are possible. If we assume that there is already an application in place that is used to review events, the ML algorithm might be integrated as an additional filter that runs in the background. Here, the important KPI is by how much the number of possible events is reduced. It might make sense to support the selection step with a custom webapp that leverages additional information from the model such as uncertainty scores or similarities. This might speed up the time needed to review a candidate. Finally, the webapp could provide access to a database and data exploration capabilities with previously recorded events for in-depth root cause analysis as well as noise quantification and classification.
In a first step, the ML problem class to be solved is a binary classification problem. The receiver operator characteristic (ROC curve) is a suitable metric for this case. In addition, concrete points on the ROC curve can be used as a metric that is easier to communicate to the different stakeholders. Examples are: When we allow 2% of the brake noise events to go undetected, we need to sort out 50% false positives; when we allow 1% of the brake noise events to go undetected, we need to sort out 70% false positives. In later stages, the ML problem can also be formulated as a classification problem with multiple classes (qualification of braking noise) or as a segmentation problem on spectrogram representations.
Data Sources and Data Curation and Methods
Acoustic data from the microphones as well as other vehicle data recorded during the test run are the data sources available for the solution. Ideally, this data is already stored in open formats such as the ASAM MDF standard. The data itself can either be stored on a local disk, in a central ASAM ODS repository or in a compatible data lake solution. In all cases, a Python API is usually available. Workflows to enrich the data with rule-based post-processing algorithms are common (e.g. converting time signals into spectrograms).
In terms of ML methods, the classification problem can be tackled by using standard CNN architectures on the spectrogram representation of the sounds (e.g. ResNet). This can be combined with additional vehicle data (e.g. brake pressure) to learn a neural net classifier in a supervised way. The type of data and the availability of other redundant sensor data makes it also very feasible to employ self-supervision techniques such as contrastive learning or weak labeling. Here, neural networks can be used as a feature extraction technique and can be combined with data-efficient and explainable techniques such as ensemble trees.
As in most use cases, the data curation choices are plentiful and can only be summarized here. Relevant candidate features from the hundreds of data channels have to be selected in close collaboration with the domain expert (i.e. the test engineer). It also makes sense to start with a single test campaign as a first data segment. This data might be biased if a lot of trigger rules have been used during the acquisition phase. It might make sense to acquire a more complete dataset to assess these biases. If historic data from different campaigns and vehicle models are used, data cleaning has to be performed to remove faulty recordings. The viability of self-supervised learning suggests an active learning approach to save annotation effort.
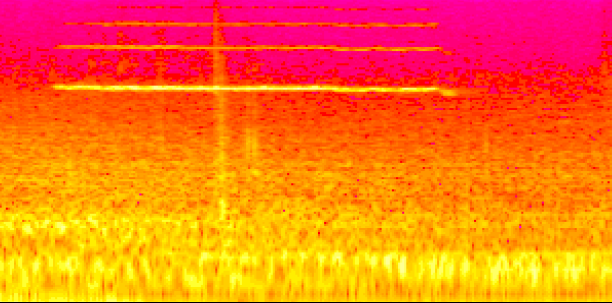
![Fig. 2: Example of a spectrogram that contains brake squeal (from [1]).](/assets/images/brake_squeal_spectrogram-2c52f14d1dad8467bff475610456fe1d.png)
Integration and Operations
The feasibility of integration and operations concept depend heavily on the AI maturity level of the respective organization. A simple proof-of-concept integration should feature a web-app where data samples can be uploaded and assessed. To generate more value, a tight integration into existing data infrastructure and the currently used analysis tool might be necessary. On the operation side, hosting the web application and managing the data samples is mandatory. For a reliable solution, suitable ML operations (MLOps) processes for model monitoring and re-training must be put in place. If it is possible to use a single model for all test campaigns, these efforts are restricted to low-frequency check-ups and model trainings. If different models must be trained for each campaign, suitable MLOps tools must put in place to perform these trainings in an automated way. Furthermore, corresponding monitoring and quality control procedures must be established.
Resources
To build the ML-based brake noise detection, several different roles and stakeholders are involved. The most important ones are: The test engineer as a user and domain expert, a data scientist who builds the data pipeline and the ML algorithm, a machine learning engineer who integrates it and infrastructure engineers who provide platform services. Especially in high performing organizations, it is typical that a single person fulfills more than one role. The concrete resource estimates in terms of capacity/person-months depend on the experience of the team as well as the available tooling and infrastructure. If the project carries a lot of risk (e.g. in terms of data availability), it makes sense to make a resource estimate towards a minimum viable product (MVP).
License cost and cloud computing fees for tooling and infrastructure should be budgeted as well. In this scenario they are probably much lower than the necessary wage costs for the project team.
Conclusions
We briefly presented a holistic concept for a data-driven solution to identify brake squeal and moan. The template based on the AI-assisted Engineering Canvas can be used to refine this use case in a specific setting. It can also inspire similar use cases in the realm of test data analysis.
Get started
Register to download an editable Powerpoint version.
If you are using the canvas for your use cases, we love to hear from you on LinkedIn
Contact us under moc.scimuner@ofni if you have any suggestions or need help for your use case.
Sources and further reading material
[1] Mauer, Günter, and Winfried Krebber. "Brake squeal and moan detection: Important requirements concerning mobile recording systems." Automobile Comfort Conference. 2006.
[2] Squadrani, Fabio (2021): Brake Noise Detection Using AI (Part 1 of 3), https://thebrakereport.com/brake-noise-detection-using-ai-part-1-of-3/
[3] Stender, Merten, et al. "Deep learning for brake squeal: Brake noise detection, characterization and prediction." Mechanical Systems and Signal Processing 149 (2021): 107181.