tl;dr
AI-based assistants offer great value to companies that design, manufacture and operate complex equipment: They can augment the knowledge of machine operators, allow for deeper insights into customer needs and enhance the collaboration of engineering teams. Retrieval augmented generation (RAG) has emerged as the de-facto standard for building such applications-specific assistants.
When designing RAG-based systems, many design choices have to be made regarding data sources, algorithms, infrastructure and application workflow. In this article, we show how the industrial AI canvas helps cross-functional teams to do this efficiently and iteratively. We also list helpful open source tooling for each task.
You can download a blank version of the industrial AI canvas here
What is Retrieval Augmented Generation (RAG)?
Chat-based assistants like ChatGPT have become increasingly popular and are used for a wide variety of use cases from coding to generating marketing content. The large language models (LLMs) that power these assistants are trained on a variety of general purpose datasets (e.g. Wikipedia, Textbooks, Common Crawl). This approach gives rise to two distinct drawbacks when directly querying LLMs in a chat-based interface:
- Limited data freshness and scope: The LLM only knows about information in the training dataset, which can be outdated and typically does not cover application-specific expert knowledge.
- Limited robustness and hallucinations: When confronted with topics and concepts that are not in the training data set, LLMs tend to make up facts in order to provide an answer.
One approach to reduce these drawbacks is to finetune an LLM on a custom dataset. However, this approach is expensive as it requires deep know-how and a lot of compute. For many use cases, this approach is not commercially viable.
A different approach is to use Retrieval Augmented Generation. Here, an LLM is used to compute embeddings over a corpus of custom training data (see Fig. 1). This can be manuals, online wikis, support ticket or any other company data source that can be supplied as text and/or image data.
When a user queries a RAG system, the question is not immediately answered. Instead an embedding is computed on the question and relevant documents first retrieved from the custom corpus via a vector database. The retrieved documents are then provided as additional context for the LLM to formulate the answer.
In this way, RAG-based assistants can not only answer highly specialized questions, they also provide a reference along with the answer. This significantly helps users to judge the reliability of the response.

Fig. 1: The Retrieval Augmented Generation (RAG) approach provides additional context in the form of relevant custom documents to the LLM model.
Industrial use cases for RAG-based assistants
Engineering, manufacturing and operating complex electro-mechanical systems is really hard. Many tasks in this domain rely on the personal experience of engineers and machine operators. RAG-based assistants can help to make complex documentation readily accessible, facilitate access to best practices and enable matchmaking with experts.
Internal use cases aim at improving collaboration and information accessability for cross-functional teams. Use cases in this area include requirement analysis, project progress reports and service support.
External use cases help users to configure, operate and maintain complex equipments. This does not only improve the value of the equipment for the user, it also helps to establish new digital services and improve the understanding of customer needs.
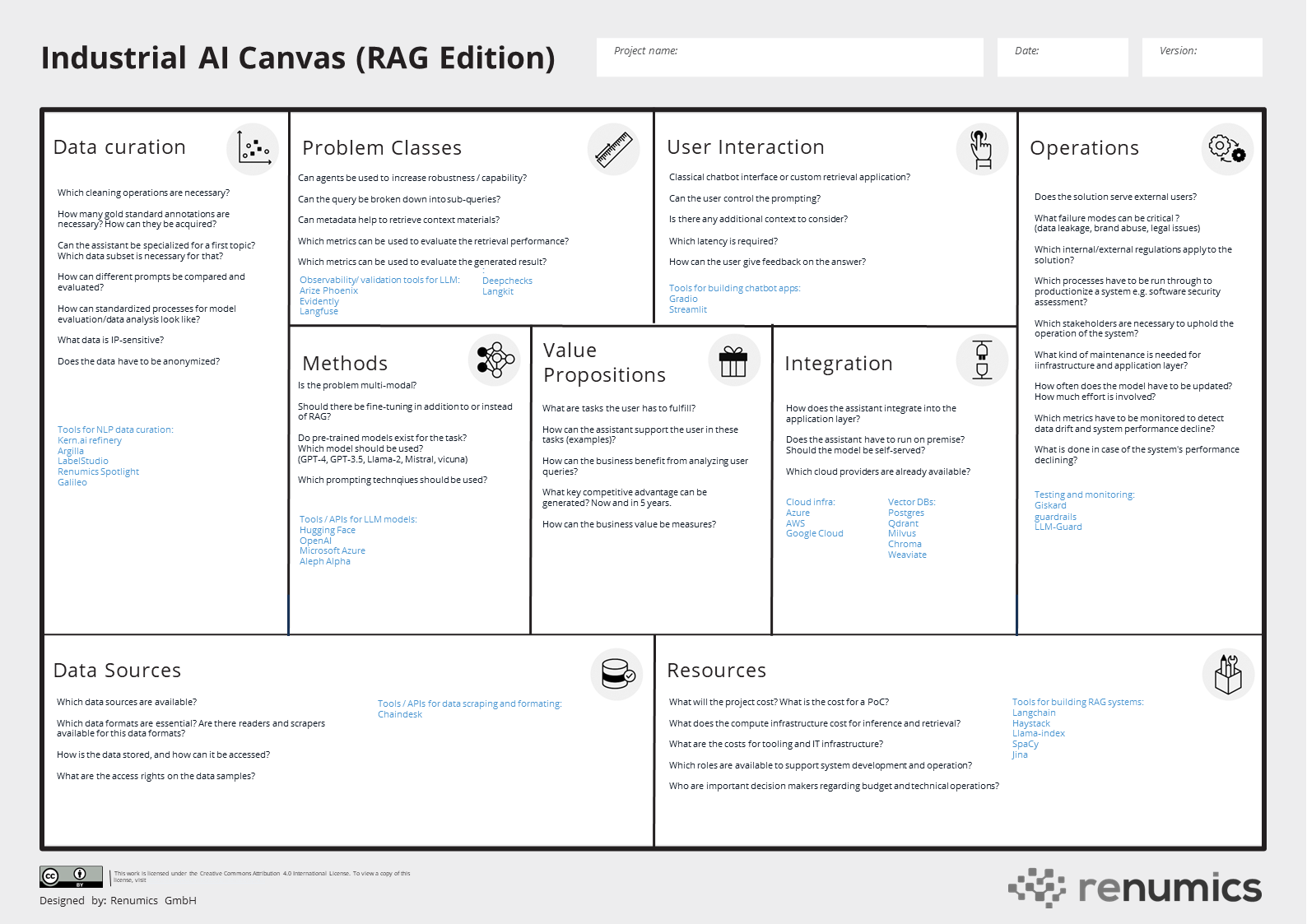
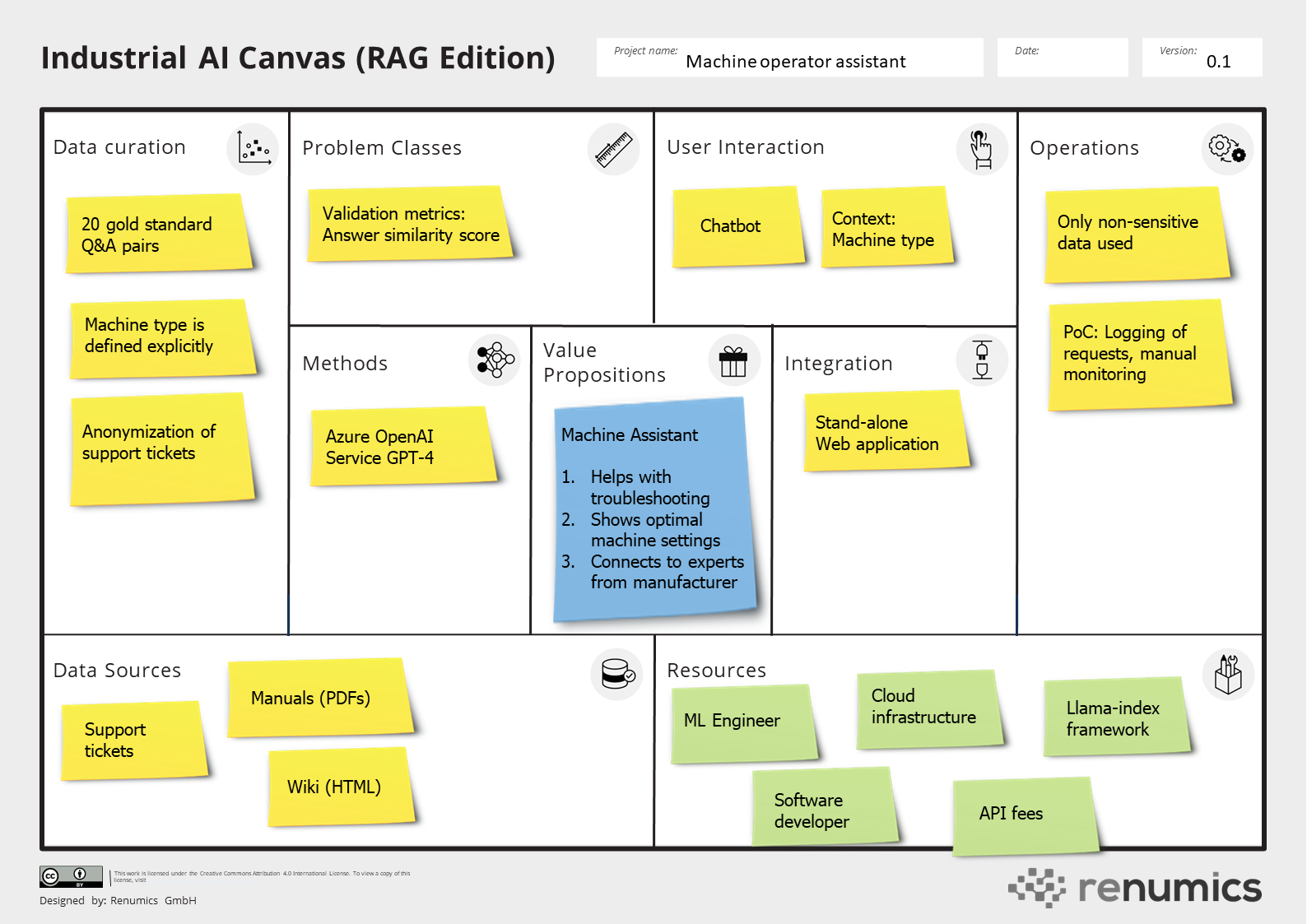
Fig. 2: The industrial AI canvas provides a template to conceptualize RAG-based systems for industrial applications. Source: created by the author.
The industrial AI canvas
Being very visual, lightweight, and collaborative, canvas-based tools can be used for both quick brainstorming sessions and also for deep dives on specific topics. The canvas method was popularized by Alexander Osterwalder in the context of business model innovation. Both the Value Proposition Canvas as well as the Business Model Canvas are now established tools for collaboratively creating and iterating on business models.
Conceptualizing business models and machine learning (ML) solutions is similar in many ways: Both revolve along common patterns but are very individual. Furthermore, mapping out a solution is highly collaborative and highly iterative due to the uncertainty and the amounts of stakeholders that are involved in the process.
The industrial AI canvas meets these challenges and provides a holistic template for AI solutions. It enables ML teams to focus on the business value created by the solution and to communicate effectively with other stakeholders (including management). It also facilites to quickly assess the feasibility of the solution by providing sensible estimates for both value provided by and resources needed for the ML-based solution.
Heart of the Canvas: Value proposition, user interaction and ML problem
Every new AI solution should start with the Value Propositions. In our workshops, we typically dive deep into defining this with the Value Proposition Canvas. Then, we carry over the key results and relevant KPIs (e.g. reduce support time by 30%) to the industrial AI canvas. Based on this target and the specifics of the current process, a first draft for the User Interaction can be established. For chat-based assistants, this step is quite straight forward. However, it still makes sense to be as precise as possible (e.g. feedback mechanism, UI integration) and to include relevant KPIs (e.g. latency, expected accuracy). In the context of RAG, the machine learning Problem Class is already broadly defined. However, it still makes sense to identify relevant metrics (e.g. retrieval, reader, answer similarity) for the concrete use case. It is also important to ponder if it makes sense to use pre- or postprocessing to increase the robustness of the solution. This includes the use of external tooling that can be controlled by the LLM (agents).
Selected tooling for this section: Streamlit (U), Gradio (UI), Langfuse (observability), Giskard (testing), deepchecks (validation, Arize Phoenix (observability)
The data science side: Data source, methods and data curation
Once a solid problem formulation is established, it becomes essential to delve into the specific questions that the system is expected to address. This requires a detailed outline of the Data Sources at your disposal, including the nature of the documents and the methods of accessing them. An integral part of the Data Curation process is the creation of a substantial set of gold standard question-answer pairs. These pairs should not only be well-crafted, but should also include relevant citations from the utilized documents. This makes sure that the information provided is both accurate and traceable. An important aspect of the data curation process is the identification of sensitive information to ensure that no personal data or intellectual property is inadvertently compromised through the system. Regarding the machine learning Methods employed, it is advisable to begin with a robust, general-purpose model like GPT-4. This choice lays a solid foundation for the system, upon which various prompting techniques and, if necessary, fine-tuning can be applied to find the optimal setup with respect to performance and cost.
Selected tooling for this section:
Renumics Spotlight (visualization), Kern refinery (annotation), Argilla (annotation), Hugging Face (modeling), openAI (model)
The application side: Integration, Operations and Resources
Integrating, operating, and maintaining machine learning (ML) solutions present significant challenges, necessitating careful estimation of the steps and resources involved even before the development of a proof of concept (PoC). A key consideration in Integration is determining whether the system can function as an independent web application or requires deeper embedding within a domain-specific platform. This decision impacts the selection of compute infrastructure, including the need for a vector database. Operations considerations are often underappreciated but vital. They encompass planning for potential failure modes, addressing security concerns, and establishing robust monitoring protocols. Additionally, clearly defining the responsibilities of various stakeholders is crucial.
The final phase involves translating the complete concept, developed using the industrial AI canvas, into tangible Resources required for the project. These resources span the spectrum from personnel (covering both domain expertise and machine learning skills) to financial aspects such as cloud computing costs and API fees.
Selected tooling for this section: Llama-index (framework), Langchain (framework), Haystack (framework), Qdrant (vectordb), guardrails (security), LLM Guard (security)
Conclusions
Incorporating RAG-based assistance into the operations of companies that design, manufacture, operate, and maintain complex products marks a significant leap in enhancing customer service, deepening customer understanding, and bolstering team collaboration. The creation of a robust and effective AI assistant involves a series of critical decisions.
To streamline this process, we have developed the Industrial AI Canvas (RAG Edition), a comprehensive tool that encapsulates all vital decisions in a single document. This canvas serves as a unifying platform, bridging the gap between various stakeholders, including domain experts, machine learning teams, and IT professionals. It not only assesses the feasibility of a RAG-based concept but also helps to assess the most suitable use case to start with.
Characterized by its agile framework, the Industrial AI Canvas proves invaluable from the early stages of ideation, allowing for continuous refinement and adaptation throughout the project’s lifecycle, thereby ensuring a cohesive and effective AI strategy.