
tl;dr
Renumics Spotlight allows you to interactively explore Hugging Face datasets with just one line of code. You can star the open source project on Github, join the Spotlight community on Discord or learn more in our documentation.
What is Hugging Face ?
Hugging Face is a platform where the AI community can share models, datasets and demos. It is often called the "Github for AI". Hugging Face hosts models for a variety of machine learning (ML) tasks and different modalities: In the context of natural language processing (NLP), this includes text classification transformer models (e.g. DistilBERT, RoBERTa) as well as large generative foundational models such as Mistral, Llama2 or Falcon. In the computer vision (CV) domain, available models include the classical Resnet, but also state-of-the-art foundational models such as CLIP, DINO or SegmentAnything. The Hugging Face transformers library also supports Whisper for transcription tasks and Audio Spectrogram Transformers (AST) for general-purpose audio analytics.
The Huggingface dataset library provides a great interface for feeding custom data into these models for training purposes. In addition, there are more than 70k public datasets available on the Hugging Face hub. These include most popular datasets from the NLP (e.g. glue, imdb), CV (e.g. CIFAR, Mnist) and audio (e.g. speech commands, audioset) domain. Having all these datasets available in the standardized Hugging Face dataset format makes it easy to pre-train and to validate different models.
Why understanding and curating your ML dataset is important
Hugging Face models can be adapted to custom problems either through fine-tuning or prompt engineering. For both applications it is key to thoroughly understand the available data for the problem. In fact, experienced data scientists know that understanding and improving the data (data curation) is the most time consuming process in an AI project.
Finding issues in unstructured data sets (e.g. corner cases, false labels) is typically a two-step process: First, an algorithmic heuristic is used to flag candidates and to identify data clusters with poor performance. Then, these clusters and data points are manually inspected. The latter part is often overlooked. Greg Brockman (Founder and president of OpenAI) writes:
“Manual inspection of data has probably the highest value-to-prestige ratio of any activity in machine learning.” — Greg Brockman
What is Renumics Spotlight ?
Spotlight is a tool to interactively explore unstructured datasets from dataframes with just one line of code. It helps you to create interactive visualizations, and leverage data enrichments to pinpoint critical clusters in your data. We are building Spotlight for teams that want to be in control of their workflows and their tooling. Spotlight offers:
- Support for most unstructured data types: images, audio, text, videos, time-series, and geometric data.
- Easy integration: You can configure and start Spotlight with just a few lines of code.
- Customizable: You can create custom visualizations and inspection lenses in the GUI or with the Python API.
- Rich examples and use cases to jump-start your data exploration journey.
Spotlight 🤝 Hugging Face datasets
The Huggingface Datasets library has several features that makes it an ideal tool for working with ML datasets: It stores tabular data (e.g. metadata, labels) along with unstructured data (e.g. images, audio) in a common Arrows table. Datasets also describes important data semantics through features (e.g. images, audio) and additional task-specific metadata.
Spotlight directly works on top of the datasets library. This means that there is no need to copy or pre-process the dataset for data visualization and inspection. Spotlight loads the tabular data into memory to allow for efficient, client-side data analytics. Memory-intensive unstructured data samples (e.g. audio, images, video) are loaded lazily on demand.
How can I get started on my own datasets ?
Getting started with Renumics Spotlight is easy. Simply install the Python package from pip:
pip install renumics-spotlight
Now you can visualize your Huggingface dataset with just one line of code. Here is an example from the computer vision domain:
ds = datasets.load_dataset('cifar100', split='test')
spotlight.show(ds)
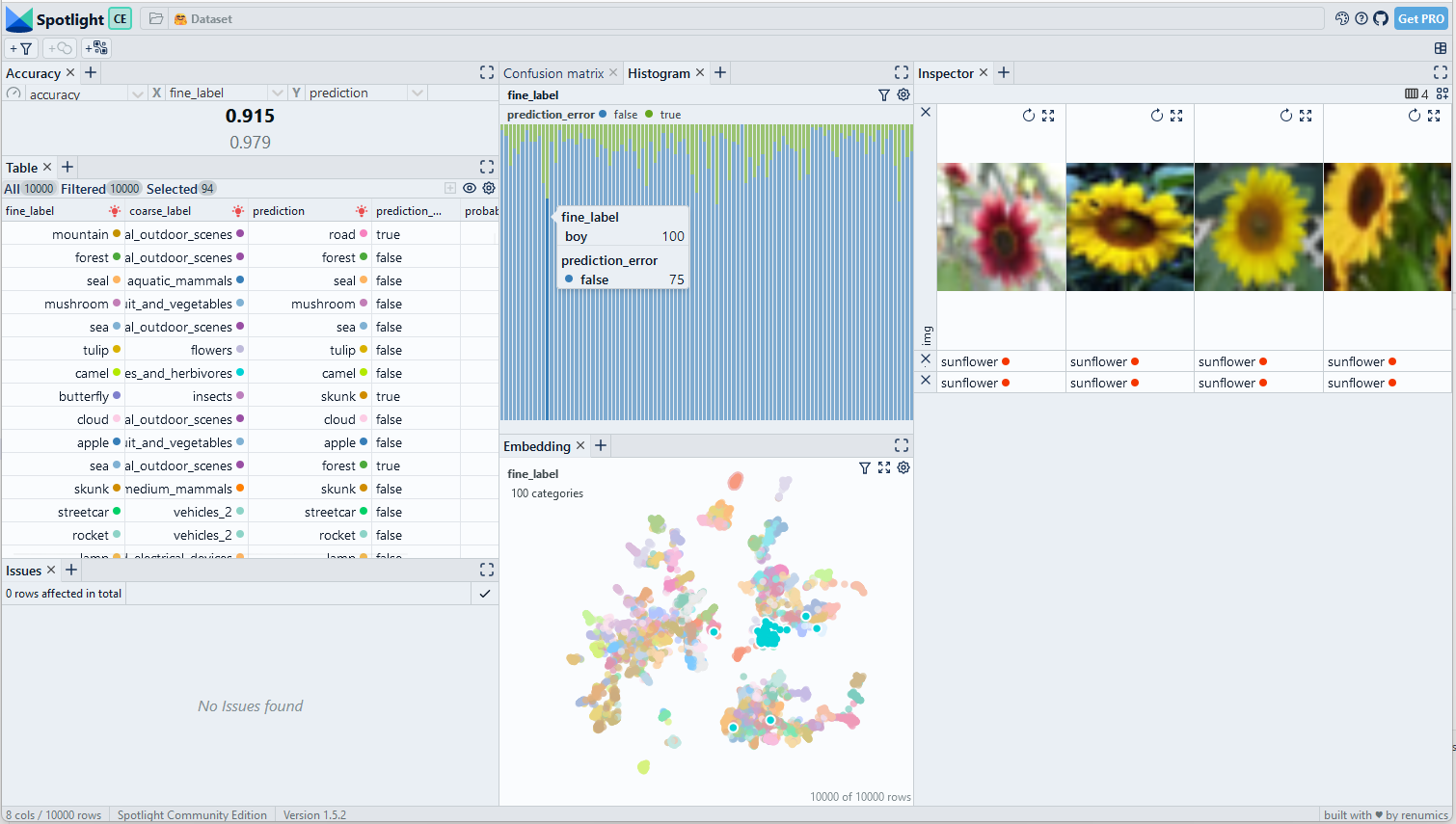
In cases where the data types are ambiguous or not specified, the Spotlight API allows to manually assign them:
label_mapping = dict(zip(ds.features['fine_label'].names, range(len(ds.features['fine_label'].names))))
spotlight.show(ds, dtype={'img': spotlight.Image, 'fine_label': spotlight.dtypes.CategoryDType(categories=label_mapping)})
What's next ?
With Spotlight you can create interactive visualizations and leverage data enrichments to identify critical clusters in your Hugging Face datasets:
- Install Spotlight: pip install renumics-spotlight
- Check out the documentation or open an issue on Github
- Join the Spotlight community on Discord
- Follow us on Twitter and LinkedIn