The acoustic and vibrational behavior of a product is a cornerstone of the user experience. This is true for product categories from vacuum cleaners or heat pumps to cars and airplanes. It is also a big differentiator especially in the high-end segments. Thus, the optimization of the vibroacoustic behavior of a product (in vehicle engineering it is referred to as NVH – Noise, vibration and harshness) is one of the most important aspects in product development.
Acoustic engineers currently use an array of sophisticated methods for their analysis. These include complex testing equipment (e.g. microphone arrays or laser scanning vibrometer) or powerful simulation tools (e.g. modal analysis or acoustic models). However, the NVH behavior is typically very complex and holistic models that are easy to use remain elusive. That is why acoustic engineers still primarily rely on their experience to analyze result data, find root causes and to recommend suitable design changes. As the amount of available test and simulation data increases, the amount of time spent to analyze this data has become a major bottleneck during product development.
In this context, machine learning offers a promising approach to leverage the increasing amount of data to derive better designs while simultaneously reducing the repetitive workload of NVH engineers. This is the main motivation behind the project VibroAI. In this joint project the IPEK Institute of the Karlsruher Institute of Technology and the simulation software vendor INTES, we investigate NVH engineers can benefit from ML-based tools in their day-to-day workflows.
Similarity-based augmented intelligence for NVH engineers
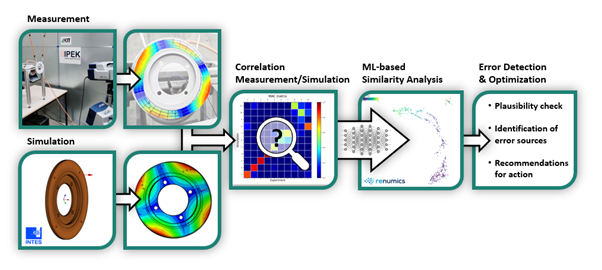
By analyzing a typical NVH analysis workflow (Fig. 1) we identified several key steps that can potentially benefit from an ML-based assistance:
- During the setup of both tests and simulations, minor errors can occur. If undetected, theses small mistakes might have a large impact on the results thus invalidating the analysis. Checking for these errors can be a tedious and time-consuming process. Automated plausibility checking through a data-driven algorithm can potentially speed up this task.
- Simulation models for a modal analysis must be matched to corresponding test data. This is challenging for several reasons: First, it requires a large amount of experience to set up a sensible initial parameter set. Additionally, the computational fine-tuning of the parameters can be tricky when mode hopping occurs as mode-tracking methods can become unreliable.
- Deriving suitable design changes to optimize the NVH behavior of a product can be difficult. Often, these choices are made based on the individual experience of the NVH engineer. An assistance that can suggest possible recommendations for action based on historic data can help with this task in several ways: It can introduce ideas and concepts that are not currently part of the individual engineer’s knowledge. In a similar fashion, such an assistance can also provide a safety net by pointing out potentially flawed solutions.
- Analyzing and optimizing the NVH behavior of a product spans the entire product lifecycle. Currently, NVH data and system models are typically not shared across different development, testing and maintenance stages. Machine learning can help to re-use knowledge across these stages.
Disc brake demonstrator part
As demonstrator part, a disk brake design was chosen. It is easy to manufacture, and the modal behavior of such basic shapes is well understood.
The parts feature some intentional small geometric deviations to build up a broad database. In parallel, simulation models are built up for the demonstrator components. Different variants containing geometric deviations are also generated by mesh morphing of the simulation models.
Subsequently, training data is generated experimentally from the demonstrators using a laser-scanning-vibrometer as well as numerically from the simulation models. The measurement data is then processed to obtain the modal parameters and mode shapes.
Detailed information on the measurement setup and the simulation model can be found in our paper "Machine Learning methods for model updating of FEM models in vibroacoustics"

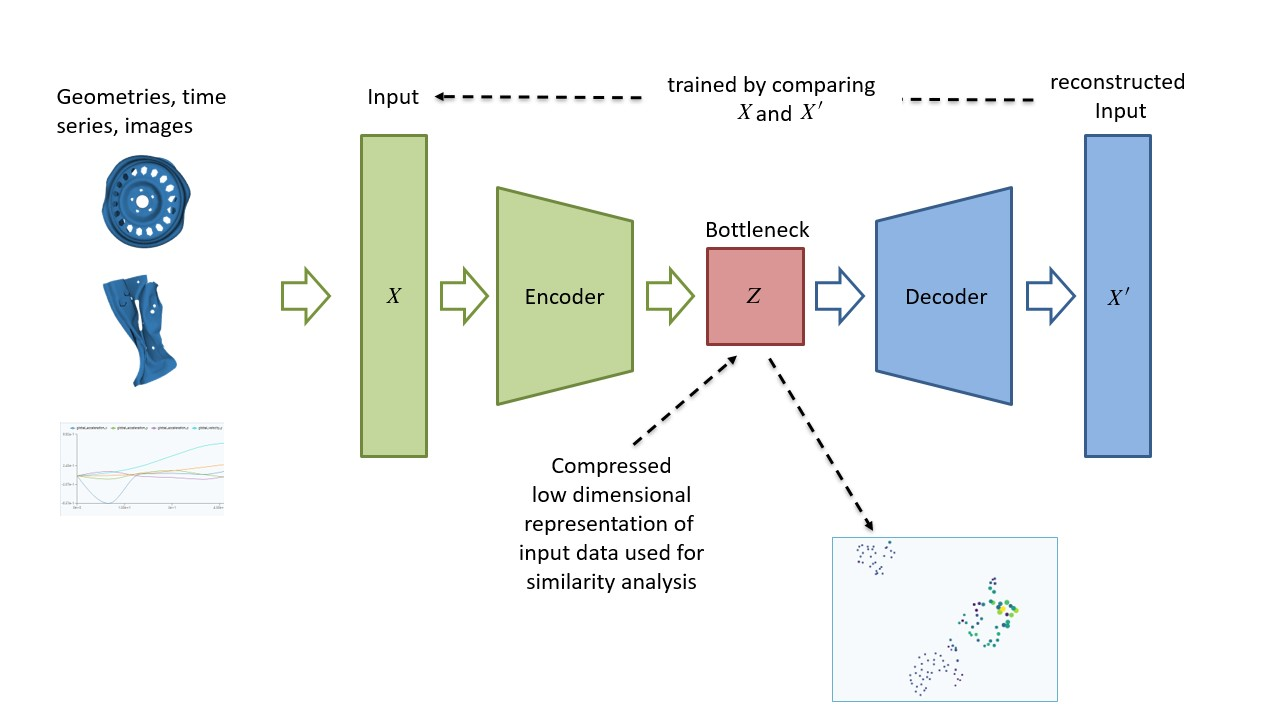
Unsupervised representation learning
The core idea of the VibroAI approach is to learn flexible similarity measures for the simulation and test data points. For this purpose, we leverage different representation learning methods such as variational autoencoders (Fig. 3).
We deliberately chose the disc brake geometry as the eigenmodes can be expressed by a pseudo 2D-representation. This allows us to leverage many standard network architectures during the project.
Within the project we focus on encoding mode shapes (i.e. displacement fields) to quickly compare test and simulation data. However, the approach can also be applied to different data types such as time series or image data.
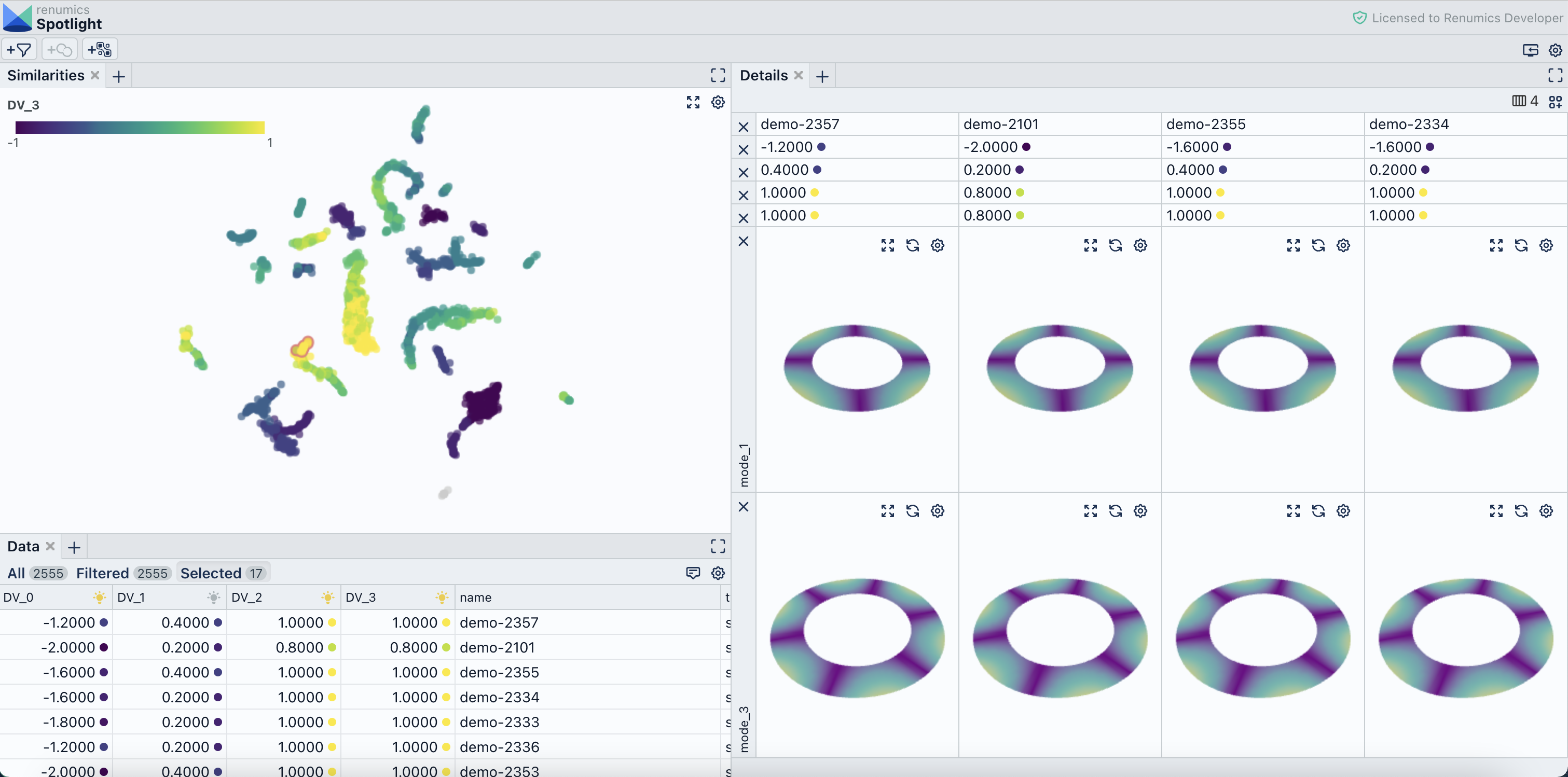
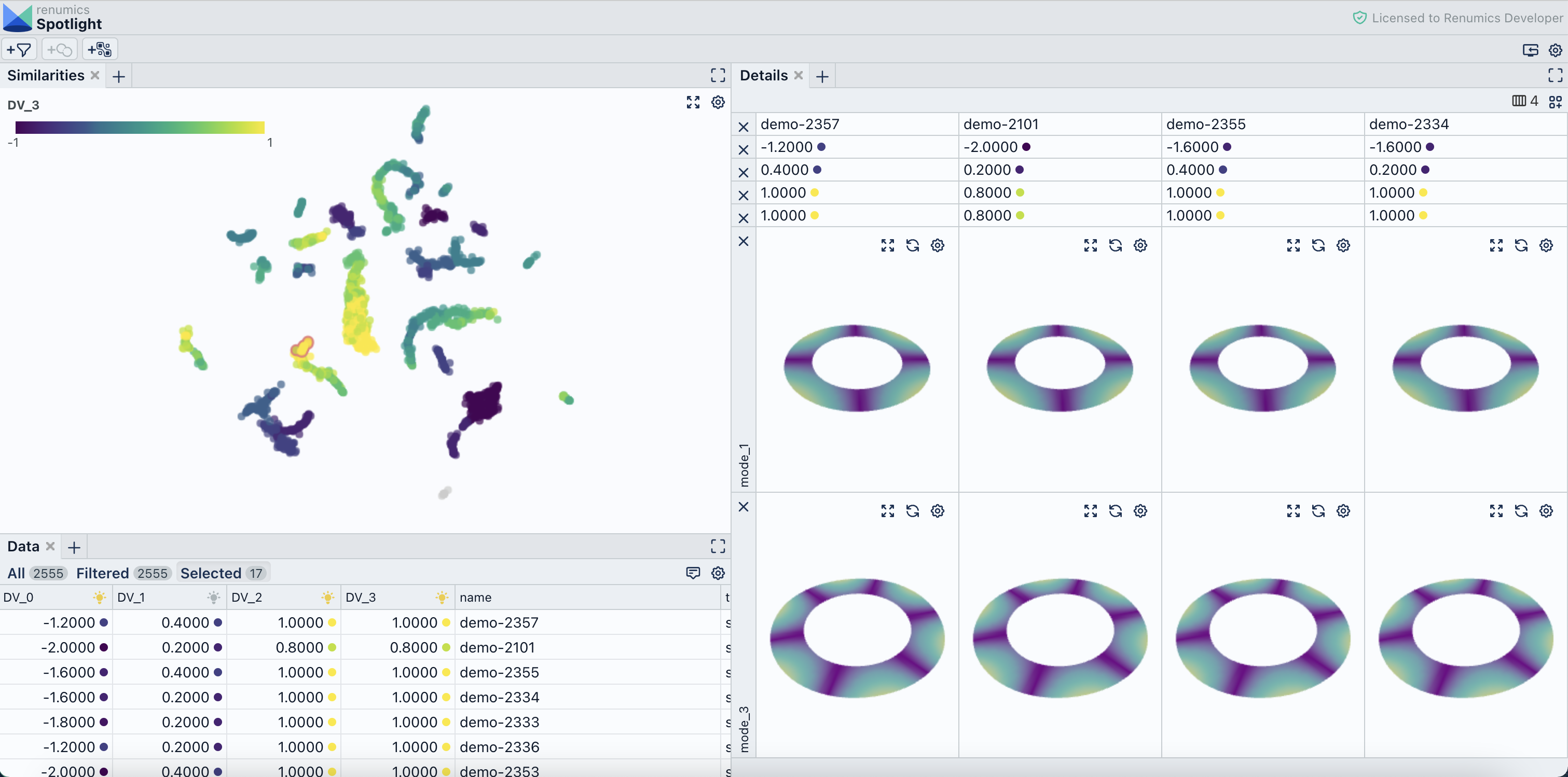
Interactive result analysis
The ability to compute expressive similarity measures is only one piece of the puzzle. Ultimately, we want to provide an assistance to NVH engineers that allow to quickly compare NVH test and simulation data. This requires intuitive user interfaces (UI) and appropriate interaction concepts that leverage computed similarities.
For this purpose, we developed a very adaptable UI based on Renumics Spotlight. We also integrated the possibility to interactively map different similarities to a 2D representation by using the UMAP technique. This functionality allows engineers to quickly define custom similarities and visualization to perform outlier analysis or data matching.
Conclusion
The amount of available test and simulation data in NVH workflows has significantly increased over the last couple of years. Consequently, the amount of time spent to analyze this data has become a major bottleneck during product development.
Within the joint project VibroAI that is partially funded by the State of Baden-Württemberg, we combine representation learning with novel user interaction concepts to build an ML-based assistance for NVH engineers. We use this approach to validate measurement setups and to match test and simulation data.
If you are interested in detailed information on the methods used (especially measurement and simulation setups), please read our paper "Machine Learning methods for model updating of FEM models in vibroacoustics" or contact us to learn more.