
How to quickly find and correct label errors
A critical task you should consider in building robust machine learning models is ensuring label consistency. This consistency is vital as inconsistent or ambiguous labels hurt the model performance and increase the amount of data needed to meet your performance goals.
While a label consistency check can be helpful in various stages of the machine learning model lifecycle, one promising strategy to find imperfect labels is to leverage model predictions. In Renumics Spotlight, we support this by reviewing model predictions on an instance level.
In this example, we use a dataset for audio classification containing 3000 audio samples. Our task here is to identify which audio samples contain siren noise.
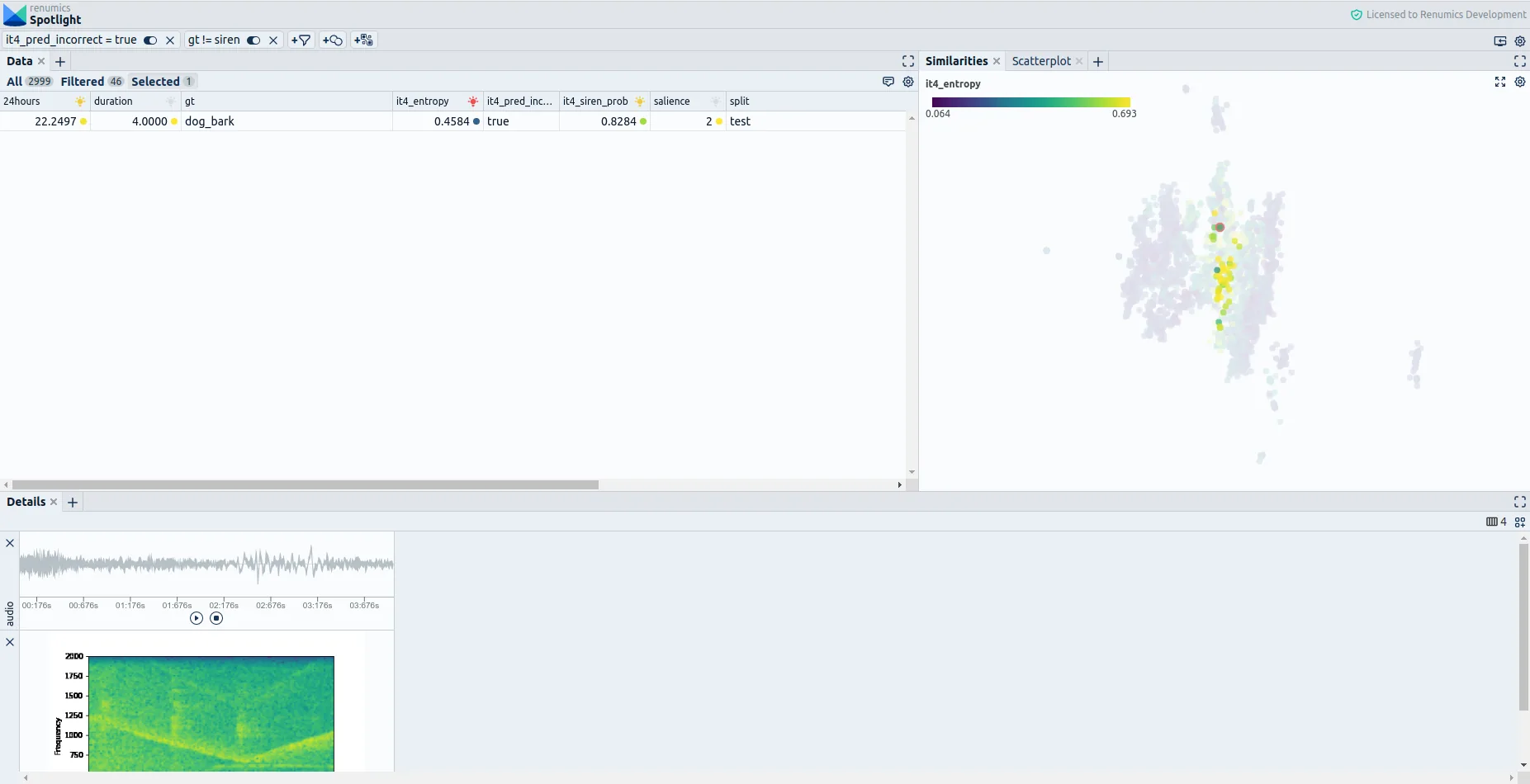
To improve annotation consistency using model predictions, we can leverage Spotlight’s Similarity Map and filtering functionalities. Concretely we can filter for audio samples that the current model misclassified as belonging to the siren class. This results in a Similarity Map that highlights data sections that the model mistakenly considers siren noise (Fig. 1). As the distances result from a pre-trained audio-embedding model, connected regions represent semantically similar audio recordings. This allows us to grasp and understand different categories of problems intuitively and quickly. To get an additional hint on which data points might be annotated inconsistently, we can check for audio samples where the model is relatively sure about its prediction. Therefore we color the filtered data points by the model uncertainty (entropy over predicted class probabilities).
For finding label inconsistencies, we should mainly look at regions where the model makes relatively few mistakes and is fairly sure about its prediction. By reviewing a low uncertainty sample, we can find an ambiguous sample containing dog bark and siren noise being labeled solely as belonging to the dog bark class. As our priority is to detect sirens, even if only present as background noise, we should relabel the sample as belonging to the siren class. This correction prevents our model from being confused by label noise and contributes to a more meaningful evaluation.