


Markus Stoll
Test engineers spend a lot of work reviewing, cleaning and understanding data. AI helps to automate these tasks. We have shown that test engineers can create a new testing report twice as fast when working alongside an AI. The AI advantage becomes even larger for highly complex tasks such as anomaly detection and root cause analysis.
Explore AI use cases for Test Data Evaluation

There are many tasks in engineering that require manual effort. ML algorithms that work on complex product development data can help to automate them. We understand how to build these models and how to integrate them into applications that move the needle in your CAX process.
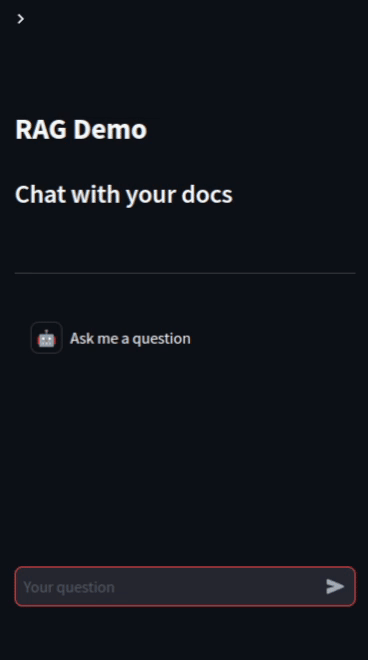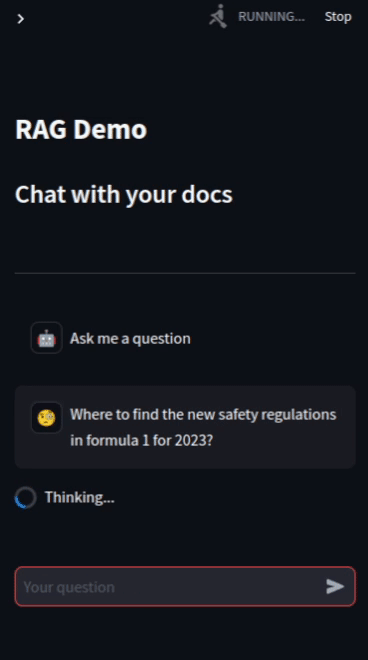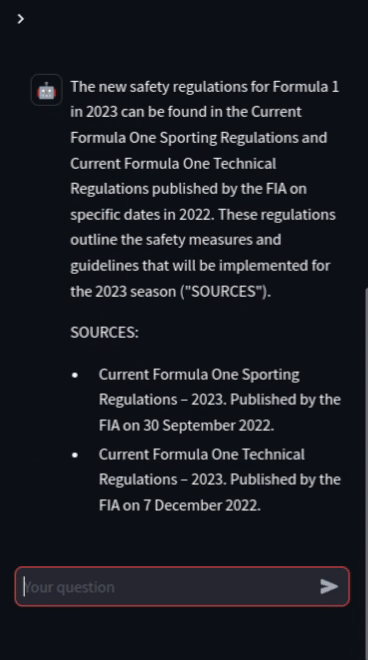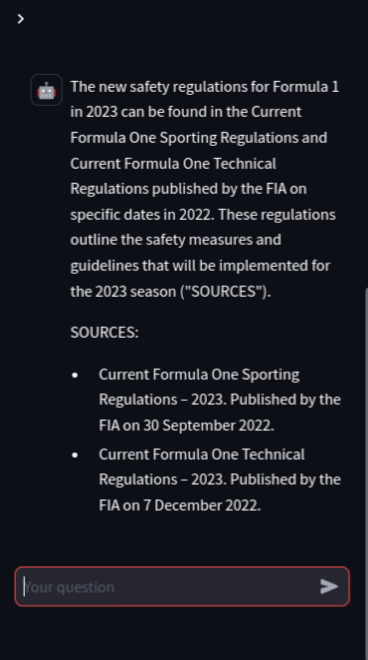
Engineers spend 30% of their time looking for information. And users often don't even bother to read manuals before calling the support hotline. With retrival augmented generation (RAG), you can quickly build assistants that can answer questions on your documents. With our experience, we can help you to create assistants that your team and your customers can trust.
Connect with Renumics to explore AI applications for your business. We are your ideal partner for industrial AI.
There's considerable buzz and many empty promises in the field of industrial AI. Throughout our journey, we've made and witnessed various mistakes.
More significantly, we have repeatedly built AI-based systems that are loved by users and that are driving value for our customers every day.
Our Approach

By integrating early, we can quickly identify any potential issues and address them before they escalate. Our data-centric approach ensures reliable and trustworthy AI systems.

We prioritize building a user-centered AI system by integrating your team as domain experts into the developing process, not just focusing on a model.

We believe in the power of collaboration and actively contribute to open-source development, fostering innovation and driving industry-wide advancements in AI technology.
Renumics is a reliable partner for your project. We are specialized in Machine Learning (ML) for the engineering industry and offer customized AI-driven solutions for analyzing test and simulation data. We possess a comprehensive understanding of AI-driven systems in the automotive industry and mechanical engineering, which enables us to assist you from concept to deployed AI systems.
Our services include data checks, proof of concepts, and full AI system development, tailored to meet your industry-specific needs. We also contribute to open-source development, driving advancements in AI technology.
Explore our services and witness how Renumics can elevate your business to new heights
We offer Workshops and Guidance to Maximize Your AI Potential and Understanding.
With a Data Check we can evaluate your data's potential for AI applications.
We build minimum viable products to validate the feasibility of your AI ideas.
Renumics delivers end-to-end services in developing, deploying, and maintaining AI systems.
At Renumics, we believe in the power of open source technology to drive innovation and deliver custom AI solutions for our clients rapidly. With our expertise in machine learning and AI system development, we leverage modern stacks without vendor lock-in to create cutting-edge solutions for the industry.

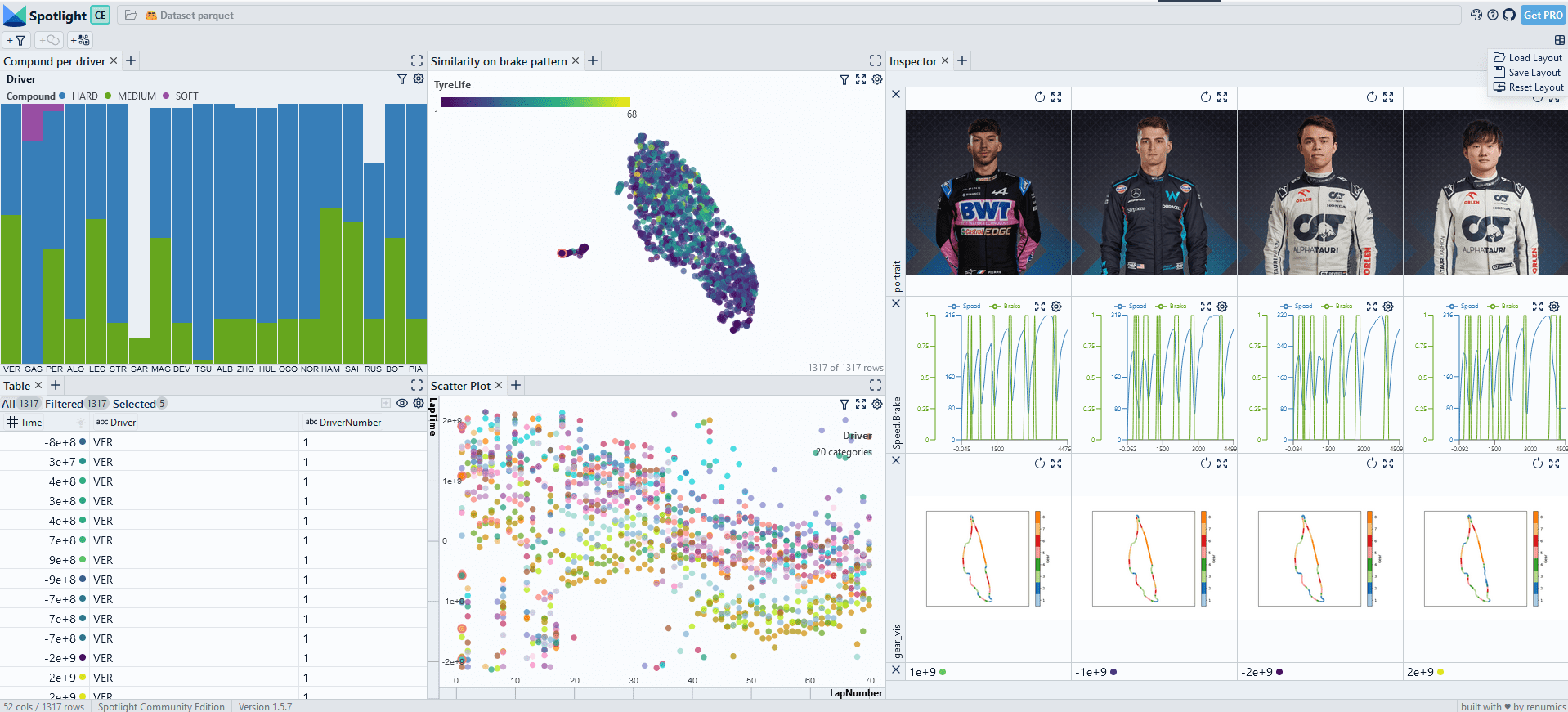
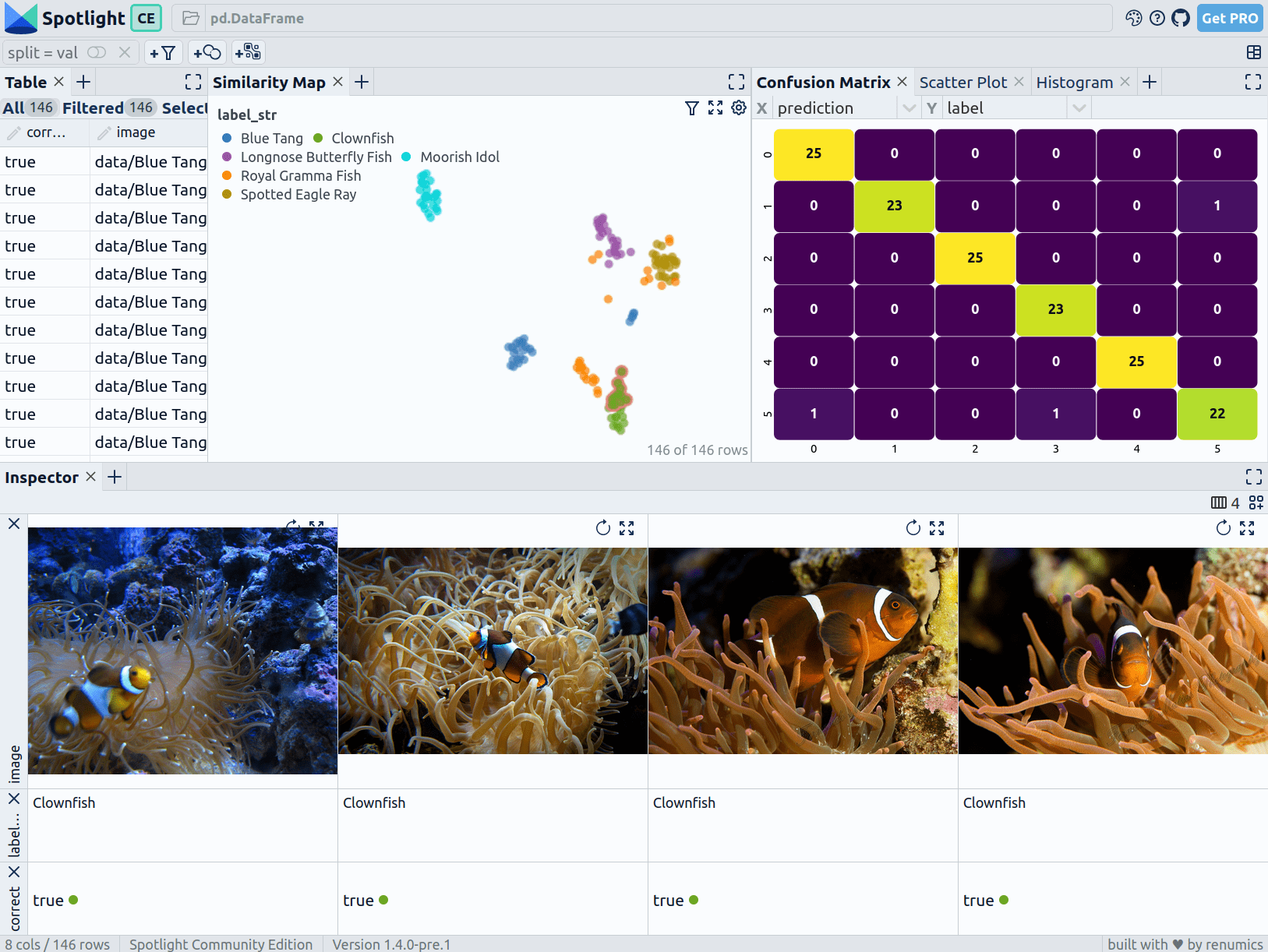
Spotlight helps you to understand unstructured datasets fast. Machine learning and engineering teams use Spotlight to understand and communicate on complex unstructured data problems.
You can quickly create interactive visualizations and leverage data enrichments (e.g. embeddings, prediction, uncertainties) to identify critical clusters in your data.
Spotlight supports most unstructured data types including images, audio, text, videos, time-series and geometric data.

Recent Posts from the Blog
Learn how we have used Spotlight to solve-real world problems. Also explore the latest news and insights on industrial AI and LLMs in our blog.