
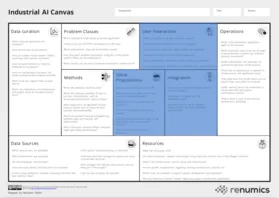
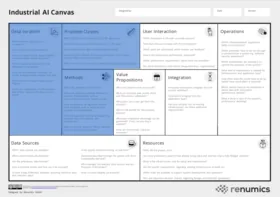
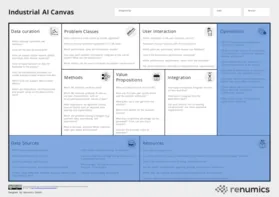
The Industrial AI Canvas
tl;dr
The Industrial AI Canvas can be a useful tool for planning data and ml-based projects.
Download the PDF of our canvas here: Industrial AI Canvas
Also check our workshop and project consulting offers under Services and our free data curation tool Spotlight.
Motivation
When embarking on a machine learning or data-driven project, it’s essential to consider various layers for planning a successful solution. Considerations here typically go from business-related questions to highly technical design considerations. However, navigating these layers can be challenging, and overlooking potential pitfalls can derail even the most promising projects.
To help mitigate these risks, we designed the Industrial AI Canvas, a canvas-based method to provide a holistic view of a machine learning-based project. Using this method early on, project teams can uncover potential problems and generate rough estimates on critical factors such as cost and human resources. It’s important to highlight that the canvas is not about planning out a project entirely in advance but instead getting an initial idea of chances and risks by considering critical key aspects. Throughout the project, the canvas can be used to document the current state and make updates as necessary.
The Business and User Perspective
When conceptualizing a successful system, the core question still has to be: Which value does my system bring to the user and the company? This ties strongly to system design aspects like User Interaction and Integration in existing processes, which is why we consider those aspects together.
Value Proposition
Whether your system generates value for the user and company is still the most crucial factor in deciding whether your system will be accepted and applied regularly. Thus it has its separate category on our canvas. Here you should ask yourself questions like:
- What are the tasks the user has to fulfil?
- What are the main pain points of the user the solution addresses?
- What gains can a user get from using the solutions?
- What is the benefit for the business process?
- What key competitive advantage can be generated?
- How can the business value be measured (KPIs)?
Integration
On few occasions, you will have greenfield projects without ties to any existing system component or process. Thus, it is vital to consider integration in existing processes AND infrastructure as otherwise, lacking adaption of the users or technical hurdles can significantly endanger your project. Typical questions you should ask yourself here are:
- How does the solution integrate into the current workflow?
- How does the solution integrate into the application layer?
- Can your solution run on the existing infrastructure? Are there additional requirements?
User Interaction
How a user interacts with a system can significantly influence the usefulness of a solution. This strongly connects to the previous paragraph about integration, as the user probably already uses specific applications, and your solution should integrate with them smoothly. On the other hand, it also interacts with the technical solution you want to design. A good user interaction can, e.g., significantly mitigate flaws in a model or even lead to better overall results. Here you should, for example, ask yourself the following questions: Which interaction is the user currently used to?
- How does the user interact with the new system? Can an improved interaction add value even without an ML-backend?
- Which parts of the workflow are automated by the system, which require user feedback, and where are the interfaces?
- How is the performance of the interaction measured? What performance threshold should be met to make the solution viable?
- Which accuracy requirements for the model derive from the workflow?
- Are there interactions that reduce the requirements on the ML model?
The Machine Learning Perspective
When thinking about user interaction, you already slowly move toward the technical implementation of your system and, therefore, questions related to machine learning and data. You might be thinking, does this even make sense to already think about this in such an early project stage? We believe it can be helpful, at least, to get an idea to outline several possible approaches (also in combination with other parts, e.g., user interaction). Also, it can help to provide rough estimates on implementation costs and uncover potential risks of specific implementations.
Problem Classes
In many cases, when solving a problem with machine learning, there will be different ways to model the problem. E.g., if the solution requires predicting the quality of an electric toothbrush from an end-of-line test, you could model this as a regression problem and predict a quality score or just classify if the product is good enough to be sold. Each variant might have pros and cons and connections to the user perspective and the technical implementation. Typical questions could be:
- Which tasks have to be solved by the ML algorithm?
- How can the user problem be translated into a machine-learning task?
- Which accuracies does each problem formulation enable?
- How does each problem formulation integrate into the overall system and what are the implications?
- Which metrics can be used to evaluate the system’s performance? Which thresholds should be met?
Methods
Even if you decide on a particular class of problems like those described in the previous section, you could potentially use hundreds and thousands of algorithms and modeling techniques to solve your machine-learning problem. E.g., you could solve your classification problem using a decision tree or an SVM. Of course, this again interacts with other areas on the canvas, e.g., certain data types or quantities of data might imply using specific techniques especially suitable for these conditions. Although, of course, this is a highly explorative area of the canvas, it can thus make sense to ask questions such as:
- Which ML methods could be used?
- Which ML methods probably fit best on use case characteristics such as structured or unstructured nature of the data etc.?
- What implications could certain algorithm choices have on important factors such as required data quantity or explainability of system decisions?
- Which are possible training strategies (e.g., training on synthetic data, pre-training, self-supervision)?
- What is the basic (minimum) solution? Which methods might give optimal performance?
Data Curation
While finding algorithms that can help you solve your problem is crucial to success, data is the part that really adds to the complexity of machine learning-based systems and can decide between success or failure. Typical data-related tasks could be acquiring sufficient and high-quality data, fixing data problems, annotating the data, and more. All these tasks potentially span all project phases and interact with various other canvas areas, such as the available data sources or the methods used for modeling. Key questions are:
- Which cleaning operations are necessary?
- How can the data be annotated?
- How can subject matter experts contribute their domain expertise?
- How can quick iteration on data be facilitated in the project?
- How can standardized processes for model evaluation/error analysis look like?
- Which tools can support data curation efforts?
- Which are implications on infrastructure and project setup do the above points have?
The Foundations Perspective
Unfortunately, even with the best business case and when considering all the above, some foundational aspects must enable your use case to some degree. E.g., if it is impossible to export data from a data management system in a way that it can be processed by a machine learning model, this could be a real blocker for using your application in production. So this category is mainly about reflecting on the current data and project landscape and everything required for initially and continuously operating your system.
Data Sources
Sadly, when building data-driven systems already, the “getting the data” and “accessing the data continuously on demand” part can be a real dealbreaker. Having a lot of ties to canvas areas such as Data Curation and Methods that build on the availability and access to data and also being related to the discipline of data engineering, this category asks questions such as:
- Which data sources are available?
- Which data formats are essential?
- Are there proprietary data formats that can only be accessed through certain tools?
- How is the data stored, and how can it be accessed?
- Is there a big difference between acquiring historical data and real-time data?
- Is the system a batch processing system or a “real-time”/streaming system and how does this relate to data sources?
- How does the data flow from the source through the system and what is potentially fed back?
- Who manages the relevant data sources and are they part of the project?
- How can data integrity be ensured?
Resources
For bringing a system to production, it is crucial to ensure the use case has enough support and, with that, has the power to use resources necessary for development and later continuous operation. These Resources can be related to infrastructure/technical, human, or financial resources.
We have seen too often that even though the use case seems promising after an initial PoC can still sink a project because those requirements were not taken into account when previously setting up the use case and were not actively managed when the project progressed. Key questions here could be:
- What will the project cost?
- Are there preliminary variants that already bring value and cost less than a fully-fledged implementation?
- What is the infrastructure cost for setup and maintenance?
- Are there specific requirements regarding existing infrastructure to build on?
- Which roles are available to support system development and operation?
- Who are important decision makers regarding budget and technical operations?
Operations
As running a system in production over a longer time is a challenge that is all too often neglected, we gave this its own category in our canvas. As you can already imagine, this also has strong ties to other categories, such as data sources, resources, and more, as many categories are relevant in different project phases with slightly different flavors. In general, the Operations category can highlight everything that is especially worth considering when considering continuously operating the system. This can span from regulatory requirements over infrastructure requirements to requirements that must be fulfilled to uphold a working and relevant machine learning model. Example key questions are:
- Which internal/external regulations apply to the solution?
- Which processes have to be run through to productionize a system e.g. software security assessment?
- Which stakeholders are necessary to uphold the operation of the system?
- What kind of maintenance is needed for the infrastructure and application layer?
- Which metrics have to be monitored to detect data drift and system performance decline?
- What is done in case of the system’s performance declining?
- How often does the model have to be updated? How much effort is involved?
Summary
We hope the Industrial AI canvas can help you plan your project and keep an overview of certain critical key areas while iterating your project.
You can download the current version as PDF here: Industrial AI Canvas
We plan on releasing more example use cases that show the use of the canvas for certain domains shortly and will link them here. So, feel free to check back or get in touch with us anytime.
Also check our workshop and project consulting offers under Services and our free data curation tool Spotlight.