Data-centric AI for Engineering and Manufacturing
Introduction
Data-centric machine learning (ML) promises to speed up model development and to increase model performance. According to the NeurIPS data centric AI (DCAI) workshop, the term represents the recent transition from focusing on modeling to the underlying data used to train and evaluate models. For the uninitiated, the term might seem odd at first glance or even tautological. Is ML not inherently data-driven anyway? Which experienced data scientist does not know that data quality is the most important part of any ML system? In this blog, we will explain how the term DCAI was coined, what separates the paradigm from model-centric ML and why it is especially important for applications in engineering and manufacturing.
Iterating the dataset instead of iterating the model
Traditionally, the ML community develops new methods for fixed benchmark datasets. While this has many advantages, it reinforces a model-centric development paradigm: The data set is fixed, and the model is improved through novel architectures or different hyperparameters. In the realm of manufacturing good examples include the SECOM data set or the Bosch Production Line Performance challenge at Kaggle. In these cases, the data set is not only fixed, but little is known about the overall setup and the recorded features. In contrast, in real use cases it is not only possible to acquire new data and new labels, but a vast amount of domain knowledge is usually available. Thus, it makes often much more sense to iterate on the data instead of iterating the model architecture. This mindset is called data-centric machine learning.
While the main ideas and principles behind DCAI have been investigated and applied for several years (including in our projects at Renumics), to the best of my knowledge the term was coined and popularized by Andrew Ng in March 2021. The idea of iterating on data was also prominently featured in Andrej Karpathy’s presentation of the Tesla data engine at CVPR 2021.
Data curation tools power data-centric ML
In practice, data scientists have always spent most of their time on building and maintaining datasets. Related tasks include data collection, cleaning and labeling as well as augmentation, feature selection and quality monitoring.
However, until now most practitioners lack efficient tools to support these data curation workflows. Instead, in-house tools are build based on Python toolkits such as Matplotlib, Plotly or labelImg. While such approaches can work well for smaller tasks, it takes valuable time to create and (more importantly) to maintain these tools. These pains grow when such tools expand from small single task apps to holistic data curation solutions. And the latter point is exactly the essence of a modern data-centric workflow: Instead of regarding data processing tasks as independent steps, a holistic data-centric perspective is adopted throughout the entire lifecycle of the ML solution. Equally important, this perspective is shared and discussed between data scientists and domain experts through highly interactive data curation tools.
Principles of data-centric AI
We have identified four concrete principles of DCAI that directly contribute to increased development speed, lower data acquisition costs and more reliable outcomes:
1. Qualitative results in addition to quantitative metrics
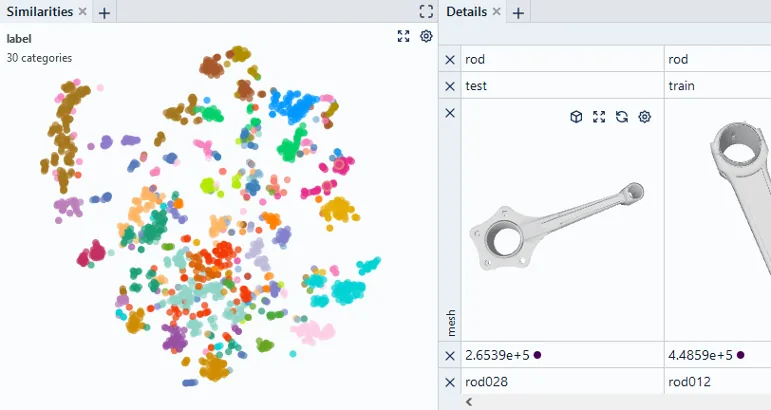
In a model-centric perspective, the model results are primarily assessed in terms of quantitative metrics such as the F1 score or a ROC-curve. In some scenarios, class-specific metrics such as the confusion matrix help to gain additional insights. In contrast, data-centric tools allow to seamlessly transition from these statistical measures into specific data segments and concrete data points. A key concept here is the similarity map based on the model’s embedding. This allows to understand where errors are occurring in the data and how the dataset can be optimized to reduce them.
2. Fusion of explainable ML and domain knowledge
ML methods not only produce final predictions but can deliver valuable information about the dataset along the way: Examples include similarity measures based on embeddings, feature importances and uncertainty scores. Data curation tools combine this information with interactive data exploration capabilities to give domain experts new insights into the data. This helps to efficiently increase data quality by eliminating outliers, correcting labels or identifying important populations within the data.
3. Use of self-supervised learning and foundational models
In a traditional modeling workflow, a significant subset of the data is labeled before a first model is trained. In contrast, a modern data curation approach starts with applying a pre-trained foundational model or a self-supervised method. The insights gained from the model help to understand the problem space and to guide additional data acquisition and labeling processes (active learning). Consequently, data acquisition and labeling costs are substantially reduced.
4. Data flywheels and model monitoring
In the model-centric paradigm, the training data remains fixed over the model lifecycle. In contrast, the largest business advantage is usually created where data-driven services are continuously improved by user feedback. Data-centric AI seeks to establish these data flywheels from day 1. Starting from the earliest problem space exploration up until the monitoring of the model in production, data curation tools help domain experts and data scientists to continuously iterate on the dataset to enhance the performance of the ML solution.
Data-centric AI for engineering and manufacturing
We believe that there are several reasons why the data-centric ML paradigm is especially useful in engineering and manufacturing applications. First, the datasets are usually small and quite unbalanced when compared to traditional CV or NLP benchmarks. This reinforces the need for good data instead of big data. In addition, the problem space and thus the datasets are complex and can only be fully understood by domain experts. Thus, data labeling must be performed by highly qualified (and therefore expensive) engineers and cannot be outsourced to a crowd. Finally, reliability and trust are a crucial factor in many use cases. Engineers want to deeply understand the limitations of the model they are working with.
All three properties together play to the strong points of DCAI: Quicker understanding of the problem space, less data acquisition and labeling costs, faster performance improvements and more transparent insights into the model behavior.
We also believe that great data curation tools are necessary to unlock these benefits and that it does not make economical sense to build such a tool from scratch for every new use case. That is why we are developing an interactive, adaptable, and intuitive data curation tool for applications in engineering and manufacturing: Renumics Spotlight.